Sourcegraph CSRF security model
This section describes Sourcegraph's security threat model against CSRF (Cross Site Request Forgery) requests, in depth for developers working at Sourcegraph.
If you are looking for general information or wish to disclose a vulnerability, please see our security policy or how to disclose vulnerabilities.
- Sourcegraph CSRF security model
- Living document
- Prerequisites
- Sourcegraph's CSRF security model
Living document
This is a living document, with a changelog as follows:
- Aug 13th, 2021: @slimsag does an in-depth analysis & review of our CSRF threat model and creates this document.
- Nov 8th, 2021: @slimsag audited all potential instances of pre-fetched content embedded into pages and found we have none, the following is NOT true (#27236):
- "Some Sourcegraph pages pre-fetch content: on the backend, data is pre-fetched for the user so that they need not make a request for the data corresponding to the page immediately upon loading it. Instead, we fetch it and embed it into the
GETpage response, giving JavaScript access to it immediately upon page load."
- "Some Sourcegraph pages pre-fetch content: on the backend, data is pre-fetched for the user so that they need not make a request for the data corresponding to the page immediately upon loading it. Instead, we fetch it and embed it into the
- Nov 8th, 2021: @slimsag adjusted CORS handling to forbid cross-origin requests on all non-API routes. (#27240, #27245):
- Non-API routes, such as sign in / sign out, no longer allow cross-origin requests even if the origin matches an allowed origin in the
corsOriginsite configuration setting. - The
corsOriginsite configuration setting now only configures cross-origin requests for API routes (nobody should ever need a cross-origin request for non-API routes.)
- Non-API routes, such as sign in / sign out, no longer allow cross-origin requests even if the origin matches an allowed origin in the
- Nov 16th, 2021: @slimsag and the Security team audited
window.contextto identify if it included any sensitive information that could be of risk.- We found no risk in this data, except for its inclusion of CSRF tokens.
- JSContext is embedded in the content of HTML pages on GET requests and included CSRF tokens. This meant sensitive, unique user data was present in GET requests that were thought to otherwise be static pages. It is likely that we had a caching vulnerability here in which user A's GET request would be cached (e.g. by an intermediary CDN) and user B's request would use User A's cached CSRF token to perform their subsequent requests. However, since we already relied on browser CORS policies and our CSRF tokens were only a secondary means of security, this was not a real vulnerability. It did however illustrate the importance of simplifying our CSRF threat model.
- Nov 16th, 2021: @slimsag removed our CSRF security tokens/cookies entirely, instead having Sourcegraph rely solely on browser's CORS policies to prevent CSRF attacks. #7658
- In practice, this is just as safe and leads to a simpler CSRF threat model which reduces security risks associated with our threat model complexity.
- This fixed the theoretical caching vulnerability with CSRF tokens mentioned in the prior bullet point. This was not a real vulnerability, but shows another example of why removing our CSRF tokens was the right choice to reduce complexity and ensure our CSRF threat model is solid and well understood.
- Dec 6th, 2021: @slimsag enabled public usage of our API routes.
- Previously, only trusted origins (e.g. including those in the site config
corsOriginsetting) were allowed to issue requests to API routes. - Now, any origin is allowed to issue requests to our API routes and, assuming they pass the authentication layer, will reach the GraphQL backend.
- Any origin is allowed to send credentials and cookies to our API routes, e.g. session cookies and access tokens via basic auth.
- Only if the request came from a trusted origin will session cookies that came in with the request be respected.
- Requests from untrusted origins will NEVER have their session cookies respected, i.e. the request will be served as if an unauthenticated user (unless it includes an access token with the request.) This is the linchpin which ensures we are still protected against CSRF in our API routes.
- Previously, only trusted origins (e.g. including those in the site config
Prerequisites
Scope
Our CSRF threat model begins and ends at the sourcegraph-frontend layer. This is the service in which all HTTP requests reaching Sourcegraph, be they a user's web browser, or via our API, ultimately go through.
This does not cover additional load balancers, proxies, CDNs, etc. that one may put in front of Sourcegraph:
- Some of our customers choose to place Sourcegraph behind nginx or apache, which may offer additional layers of security.
- For Sourcegraph.com we place Sourcegraph behind Cloudflare and it's WAF, for additional security, rate limiting, etc.
- For managed instances, we place Sourcegraph behind Google GCP's Cloud Load Balancer and Cloud Armor. details here
What is CSRF, why is it dangerous?
See also: OWASP: CSRF
CSRF (Cross Site Request Forgery) is when a legitimate user is browsing another site, say either attacker.com (ran by a malicious actor), or google.com (a legitimate site, perhaps running code by a malicious actor) makes requests to your own site, say sourcegraph.com, and is able to perform actions on behalf of the user that they did not intend to, using their own authentication credentials—often unbeknownst to them.
This can happen in many forms:
- GET, POST, etc. HTTP requests made via JavaScript
- GET HTTP requests made by
<img>tags requesting images - POST HTTP requests made via HTML
<form>submissions. - ...
For example, say a Sourcegraph user clicks a malicious link and Sourcegraph is not protected against CSRF. This would mean that, for example, a <form> element could be silently submitted in the background to perform destructive actions on behalf of the user using Sourcegraph's API—such as deleting data on Sourcegraph.
How is CSRF mitigated traditionally?
There are multiple ways in which CSRF is protected against in the modern web, including:
- Using custom request headers, relying on browser's Same Origin Policy restriction which says that only JavaScript can be used to add a custom header, and only within its origin by default. Browsers do not allow JavaScript to make cross origin requests with custom headers by default. This depends on CORS being properly configured and managed.
- Limiting authentication methods, for example not allowing cookie-based authentication at all, such that even if a cross-site request is possible, implicit authentication is not.
- Use of CSRF tokens in AJAX requests, and in form submission parameters.
There are more mitigation techniques, and risks, that you should be aware of. See OWASP: CSRF prevention cheat sheet
Sourcegraph's CSRF security model
Diagrams
These diagrams cover our CSRF security model at a high level (click to expand), the document below elaborates in greater detail.
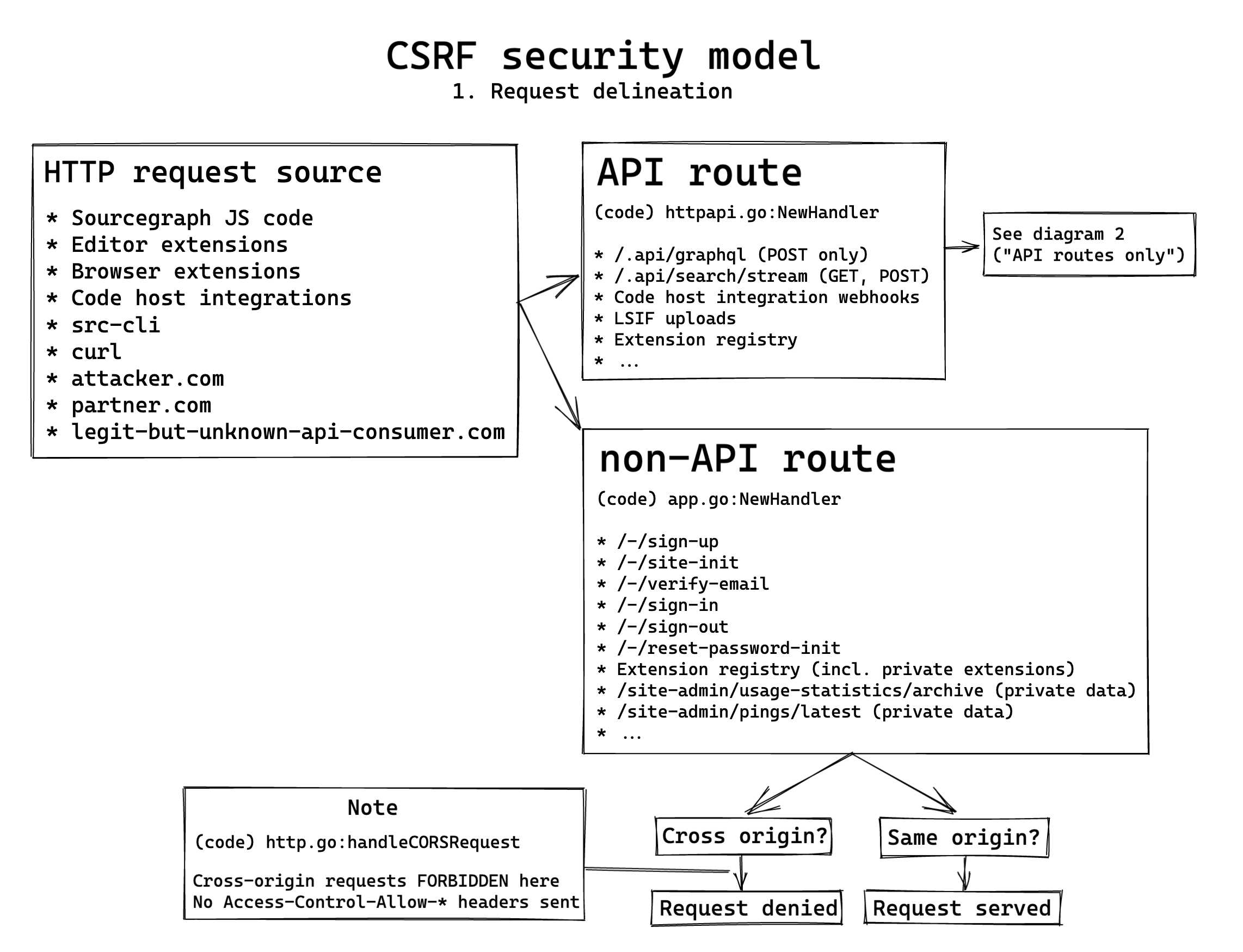

Request delineation: API and non-API endpoints
In Sourcegraph, we delineate between two types of requests that reach the frontend (generally the only place HTTP requests make their way into Sourcegraph):
- Those under
/.api- This includes all GraphQL requests.
- This includes the search streaming endpoint.
- Those not under
/.api- This includes static page serving.
- This includes UI routes like login, logout, etc.
Having a clear separation between Sourcegraph's endpoints between API and non-API endpoints makes it easy for us to reason about the security model of each in relative isolation. It also allows us to ensure all security middleware for each endpoint uniformly applies to all of our API endpoints, or all of our non-API endpoints, with ease and eliminates the need for per-endpoint security analysis.
Where requests come from
The delineation of API and non-API endpoints is very important because we can always assume endpoints not under /.api are being made by browsers or web crawlers: no other client would make these requests reasonably. Our API endpoints, however, can be requested by a vast myriad of clients:
- The Sourcegraph browser extension, which browsers provide a distinct ORIGIN for (separate from the domain they are executing on.)
- The
srcCLI, running on dev laptops, in CI pipelines, on servers, etc. - Users via
curlor various programming languages. - Code host integrations, e.g. the Sourcegraph plugin running server-side on a Bitbucket Server / Bitbucket Data Center instance—or GitLab's integration.
- Other websites, such as e.g. github1s.com using our GraphQL API to power various features.
- Editor extensions (potentially in the future, not today)
- The Sourcegraph application itself (however, most often this goes through
/.internalwhich is unauthenticated and never exposed publicly.)
Non-API endpoints
Non-API endpoints are generally static, unprivileged content only
Aside from the following exclusions, non-API endpoints only serve static, unprivileged content only. However, the two exclusions to this are very notable:
A note about window.context
window.context is served with each request. For example, if you make a request via curl https://sourcegraph.com/search you'll find each GET request for a page introduces context to JavaScript. This only contains unprivileged, public content—which is very important as otherwise it could be vulnerable to caching (e.g. if Cloudflare caches a GET request for user A and serves it to user B later):
<script ignore-csp>
window.context = {"externalURL":"https://sourcegraph.com","xhrHeaders":{"X-Requested-With":"Sourcegraph","x-sourcegraph-client":"https://sourcegraph.com"},"userAgentIsBot":false,"assetsRoot":"/.assets","version":"105021_2021-08-13_2c6eb84","isAuthenticatedUser":false,"sentryDSN":"https://[email protected]/1391511","siteID":"SourcegraphWeb","siteGQLID":"U2l0ZToic2l0ZSI=","debug":false,"needsSiteInit":false,"emailEnabled":true,"site":{"auth.public":true,"authz.enforceForSiteAdmins":true,"update.channel":"release"},"needServerRestart":false,"deployType":"kubernetes","sourcegraphDotComMode":true,"billingPublishableKey":"pk_live_1LPIDxv3bZH5wTv9NRcu9Sik","accessTokensAllow":"all-users-create","allowSignup":true,"resetPasswordEnabled":true,"externalServicesUserMode":"public","authProviders":[{"isBuiltin":true,"displayName":"Builtin username-password authentication","serviceType":"builtin","authenticationURL":""},{"isBuiltin":false,"displayName":"GitHub","serviceType":"github","authenticationURL":"/.auth/github/login?pc=https%3A%2F%2Fgithub.com%2F%3A%3Ae917b2b7fa9040e1edd4"},{"isBuiltin":false,"displayName":"GitLab","serviceType":"gitlab","authenticationURL":"/.auth/gitlab/login?pc=https%3A%2F%2Fgitlab.com%2F%3A%3A51686001d882eae9c23bbc3d976ca07ba52c5b14fd099230a1463ac9c37f2b8b"}],"branding":{"brandName":"Sourcegraph"},"batchChangesEnabled":false,"codeIntelAutoIndexingEnabled":true,"productResearchPageEnabled":true,"experimentalFeatures":{"jvmPackages":"enabled","ranking":{"maxReorderQueueSize":16},"rateLimitAnonymous":500,"search.index.branches":{"github.com/go-yaml/yaml":["v2","v3"],"github.com/kubernetes/kubernetes":["release-1.17"],"github.com/sourcegraph/sourcegraph":["3.17","v3.0.0"]}}}
window.pageError = null
</script>
Exclusion: username/password manipulation (sign in, password reset, etc.)
The following are distinct non-API routes, registered under non-API endpoints. They inherit the middleware for handling authentication based on session cookies, and utilize the same CSRF protection as other non-API endpoints:
- Sign up
- Site initialization (admin account creation)
- Sign in
- Sign out
- Reset password
- Reset password code entry
- Verify email
- Checking if username is taken
They are registered here in code.
Risk of CSRF attacks against our non-API endpoints
Non-API endpoints never allow API-like access (there are no traditional REST-like APIs here, there are no create/delete/modify actions these endpoints can perform), there is no risk in a CSRF attack aside from the window.context content (which has no sensitive or user-specific data) and the potential for using the session cookie (which is mitigated through other means, see below.)—however this is NOT true for the exclusions listed above (Exclusion: username/password manipulation (sign in, password reset, etc.).) It is therefor paramount that we defend against CSRF on the routes described by these exclusions. See "How we protect against CSRF in non-API endpoints" below.
With all of this in mind, it is worth calling out that:
- IF we had no protection at all against CSRF on these routes (no CSRF tokens/cookies and a CORS response header directly mirroring the requesting origin with authentication allowed)
- IF embedded
windowcontent was not a risk (it is not today) - THEN we would not be at risk of CSRF attacks at all, because even if
<form>,<img>, and JavaScript on foreign pages could make requests to Sourcegraph's HTTP API:- The API routes are protected (they forbid cookie-based authentication unless a custom
X-Requested-With: Sourcegraphheader is present, more on this below.) - The non-API routes would be dumb, content-serving routes only. There is no create/delete/modify action. It effectively would be dumb, static-content web serving endpoints only.
- HOWEVER, we would be subject to CSRF attacks in the aforementioned "Exclusion: username/password manipulation (sign in, password reset, etc.)" routes above.
- The API routes are protected (they forbid cookie-based authentication unless a custom
How we protect against CSRF in non-API endpoints
We rely solely on browser's CORS policies to prevent against CSRF attacks in our non-API endpoints:
- We only allow trusted domains in our CORS handling policy.
- Site admins can configure trusted CORS domains via the site configuration's
corsOriginsetting, but this setting DOES NOT affect our response to these non-API endpoints (cross-origin requests to non-API endpoints are always denied.) - This is our only means of protecting against CSRF. It applies both to the static-content-serving routes, as well as to the username/password manipulation endpoints described above.
In Nov 2021, we removed CSRF tokens which increased complexity of our security model and provably introduced security risks. See the "Living document" section above for more information.
API endpoints
All mutable and privileged actions go through Sourcegraph's API endpoints
All mutable and privileged actions go through Sourcegraph's /.api endpoints:
- Want to view potentially privileged search results? That is through our GraphQL
/.api/graphqlendpoint or (future)/.apisearch streaming endpoint. - Want to create, delete, or modify anything? That is through our
/.apiendpoints.
The only mutable, privileged actions that do not go through Sourcegraph's /.api endpoints are the aforementioned "Exclusion: username/password manipulation (sign in, password reset, etc.)" routes above.
Authentication in API endpoints
Sourcegraph's API endpoints offer multiple forms of authentication for different use-cases:
- Session cookies, via the
session.CookieMiddlewareWithCSRFSafetymiddleware. This allows session cookie authentication iff one of the following is true:- The request originates from a trusted origin (same origin, browser extension, or an origin in the site config
corsOriginallow list.) - The
X-Requested-Withheader is present, which is only possible to send in a browser if the CORS preflight check preceded the request successfully. (see the cors standard for details.)
- The request originates from a trusted origin (same origin, browser extension, or an origin in the site config
- Authentication tokens, created in the Sourcegraph UI (also via the API)—checked through the
AccessTokenAuthMiddlewareand specified by either:- The basic auth
usernamefield. - The
Authorizationheader, in eitherAuthorization: token <token>orAuthorization: token-sudo ...form with a user to impersonate in the header value somewhere.
- The basic auth
The above forms of authentication are allowed iff the request first is able to make its way through the API authentication middleware, which ensures that instances protected by e.g. OIDC or other forms of SSO are considered. Often, for example, allowing the request to go through without using the SSO provider iff the request has an access token present. Otherwise requiring the SSO provider sign off on the request, effectively.
The linchpin which ensures our API endpoints are not vulnerable to CSRF is in how we do not respect the session cookies included in requests unless the request came from a trusted origin. This is critical because we allow authenticated requests (including session cookies) to be sent to us with requests from ANY origin, e.g. attacker.com may issue a POST request via JavaScript or an HTML <form> to sourcegraph.com and the browser will include session cookies automatically. The request will pass CORS, because we allow API requests from any origin. BUT because the request did not come from a trusted origin, session cookies will not be respected-the request will not be treated as authenticated-and so CSRF is not possible.
How browsers authenticate with the API endpoints
Session cookies. Upon page load, users are given the session cookie and the session.CookieMiddlewareWithCSRFSafety middleware allows the request because:
- It is either from the Sourcegraph origin itself.
- OR it comes from the Sourcegraph browser extension origin (which is a unique origin ID hash given to browser extensions by Chrome/Firefox)
- OR it is an allowed origin in the
corsOriginsite configuration, it is a non-simple CORS request made withX-Requested-With: <anything>
How we protect against CSRF in API endpoints
There are a few ways in which Sourcegraph's API endpoints protect against CSRF:
- First and foremost, by restricting session cookie-based authentication. As described above, session cookie authentication is prohibited in non-simple CORS requests which means cookies CANNOT be used to authenticate a Sourcegraph API request unless it comes from an allowed origin, passing the browser's CORS policy checks. This is the primary means by which we protect against CSRF in our API endpoints.
- Secondarily, by providing an
Authorizationheader or basic auth with an access token. This is not possible for an attacker to provide through indirect means; they would have had to convince the user to provide them with an access token.
Known issue
CSRF protection in our API endpoints is too aggressive, leading us and customers to do more risky behavior than should be required. This is a weak point in our security model that we plan to address.
Because of point #1 above (we allow session based authentication iff the request passed CORS policy checks), it is not possible for anyone currently to use the Sourcegraph API endpoints from other, non-explicitly-allowed domains. For example:
- We cannot use the Sourcegraph search API from sourcegraph.com
- People cannot use the Sourcegraph.com GraphQL API from their own websites, even in authenticated form (i.e. public resolvers only)
- Customers cannot use the Sourcegraph API from their private instance on their own internal tool websites—even by having users provide an access token. The request would be forbidden as it would not pass the CORS preflight request.
The only workaround for this currently is to add the "trusted" domain to the corsOrigin site configuration setting. Doing so is vastly more privilege to give a domain than is often desired:
- If the desire is only to grant the domain token-based authentication to the API, it does not do that. It grants session-based auth.
- If the desire is to grant only API access, it does not do that either. It also grants the ability to perform CSRF against other non-API endpoints, such as password reset endpoints.
In general, people want to make API requests from other domains—and that is NOT the same as adding an allowed corsOrigin which is a much broader level of trust of a domain than just allowing API requests.
Improving our CSRF threat model
I @slimsag advise we make the following key improvements to our CSRF threat model in order to improve security, product reliability, and reduce risky behavior of both developers at Sourcegraph and customers on their own private instances:
Eliminate the username/password manipulation exclusion
This may be completed at ANY time. It has NO pre-requisites.
If you read "Exclusion: username/password manipulation (sign in, password reset, etc.)" you will clearly see why we've ended up in the state where we have a third type of endpoint: not an API, but a static page-serving endpoint, but something in-between. It's understandable we've arrived here, and there is no immediate threat with this structure—but it's out of place.
We would do well to:
- Place these routes into a separate category, so we have "(1) API endpoints, (2) non-API endpoints, and (3) user signup endpoints" or similar.
- The routes should be easily identified based on URL path—they should be under a common prefix, not under separate URLs as they are today.
- We should ensure the logic for registering these routes is under a distinct location. Today, they are registered under, and inherit all of the middlewares of, the non-API page routes. That is not ideal and could be risky long-term if that logic changes at all without an understanding of how it could impact these "UI routes" (as they are called in code.)