Auto-indexing
With Sourcegraph deployments supporting executors, your repository contents can be automatically analyzed to produce a code graph index file. Once auto-indexing is enabled and auto-indexing policies are configured, repositories will be periodically cloned into an executor sandbox, analyzed, and the resulting index file will be uploaded back to the Sourcegraph instance.
Language support
Auto-indexing is currently available for Go, TypeScript, JavaScript, Python, Ruby and JVM repositories. See also dependency navigation for instructions on how to setup cross-dependency navigation depending on what language ecosystem you use.
Lifecycle of an indexing job
Index jobs are run asynchronously from a queue. Each index job has an attached state that can change over time as work associated with that job is performed. The following diagram shows transition paths from one possible state of an index job to another.

The general happy-path for an index job is: QUEUED_FOR_INDEXING, INDEXING, then INDEXING_COMPLETED. Once uploaded, the remaining lifecycle is described in lifecycle of an upload.
Index jobs may fail to complete due to the job configuration not aligning with the repository contents or due to transient errors related to the network (for example). An index job will enter the INDEXING_ERRORED state on such conditions. Errored index jobs may be retried a number of times before moving into a permanently errored state.
At any point, an index job record may be deleted (usually due to explicit deletion by the user).
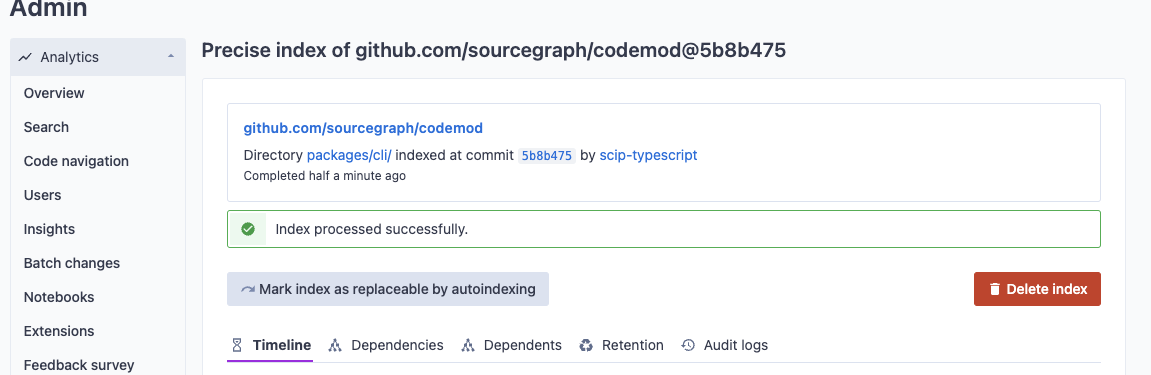
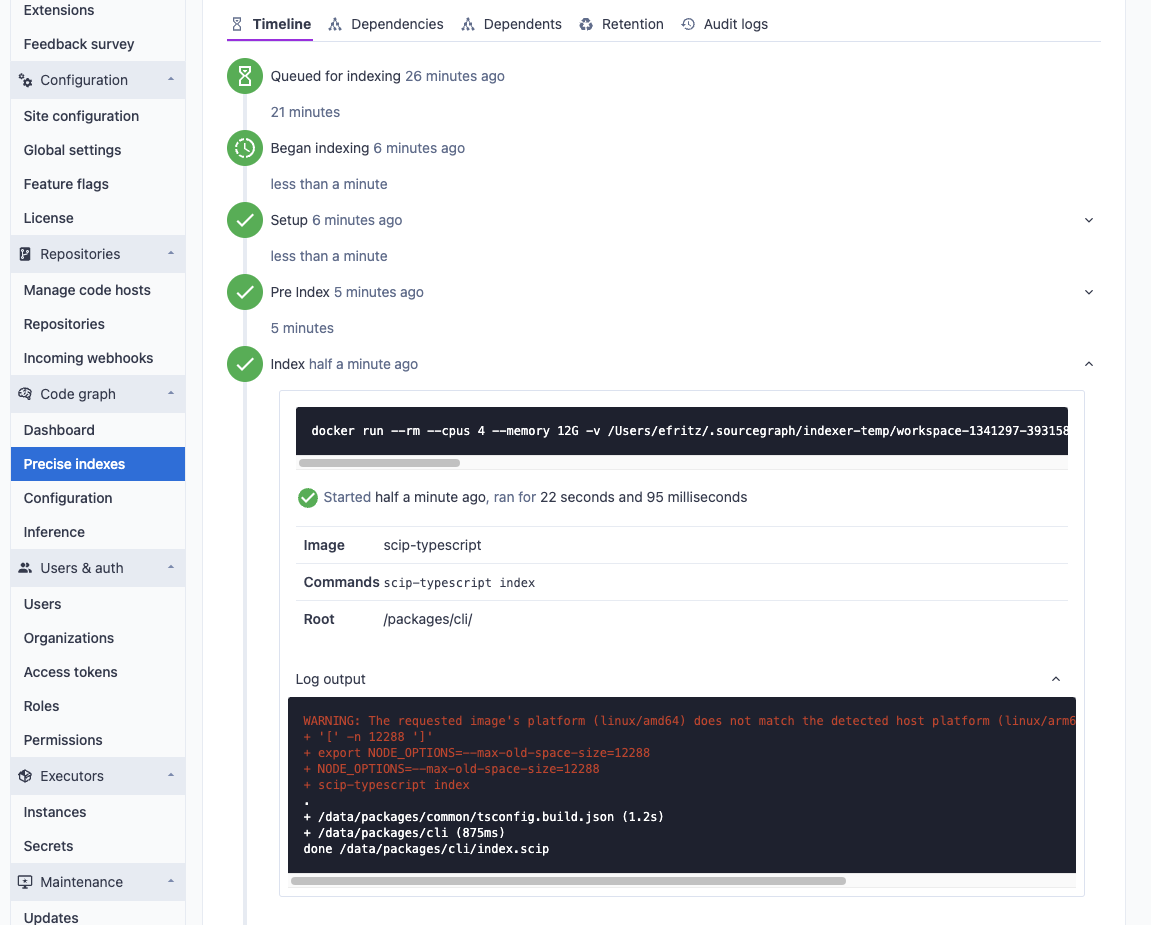
Lifecycle of an indexing job (via UI)
Users can see precise code navigation index jobs for a particular, repository by navigating to the code graph page in the target repository's index page.
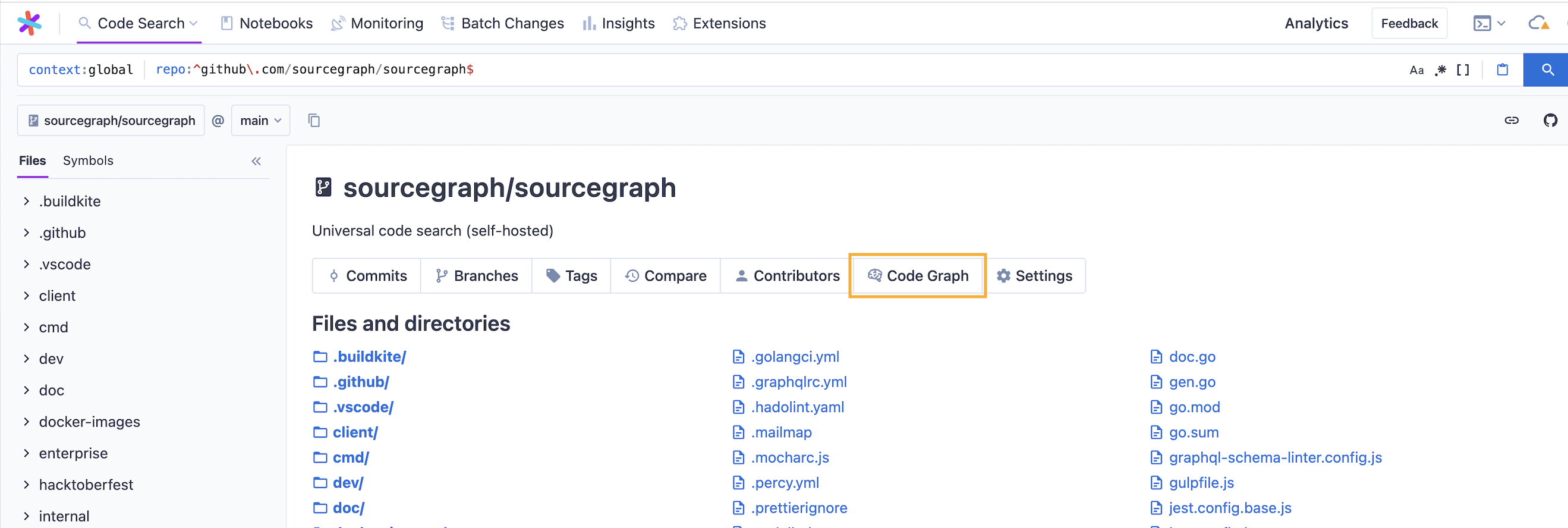
Administrators of a Sourcegraph instance can see a global view of code graph index jobs across all repositories from the Site Admin page.
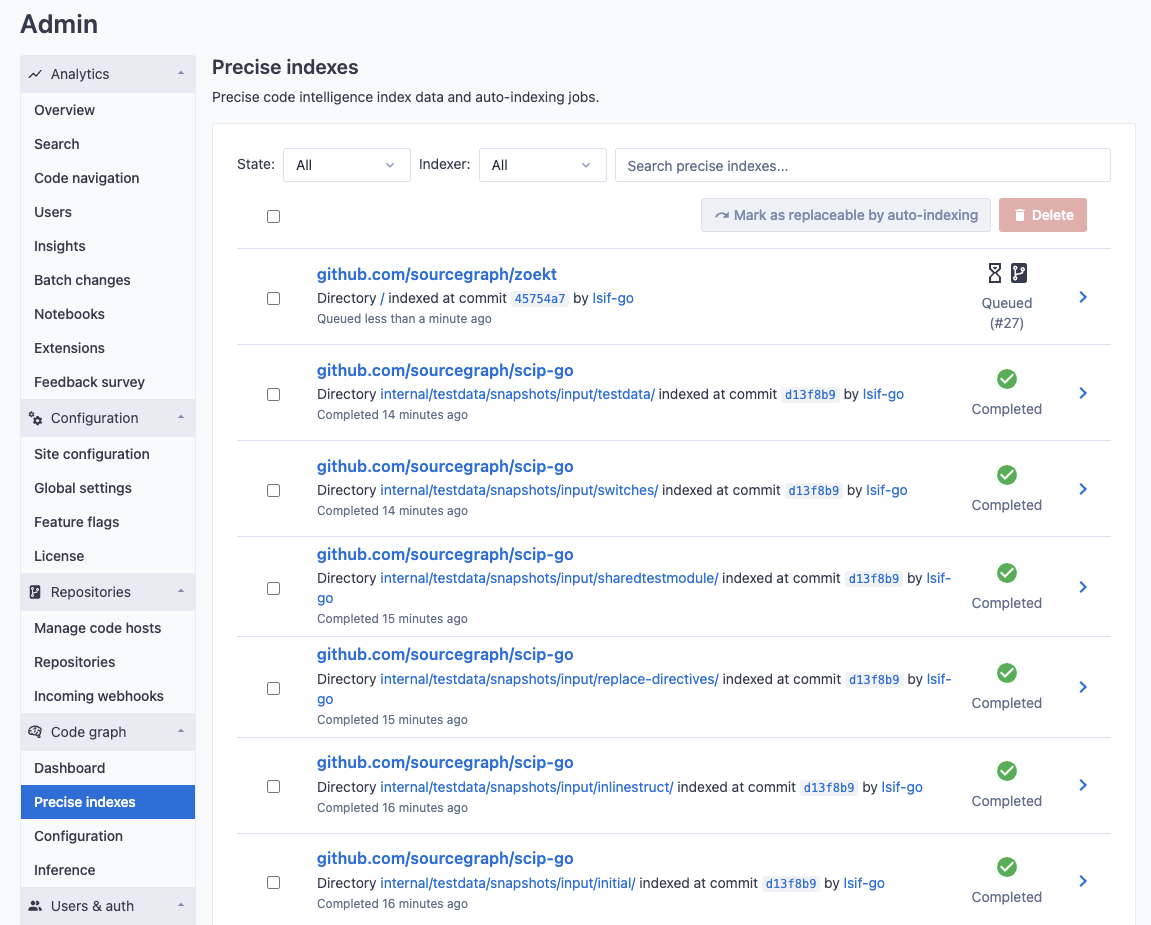
The detail page of an index job will show its current state as well as detailed logs about its execution up to the current point in time.
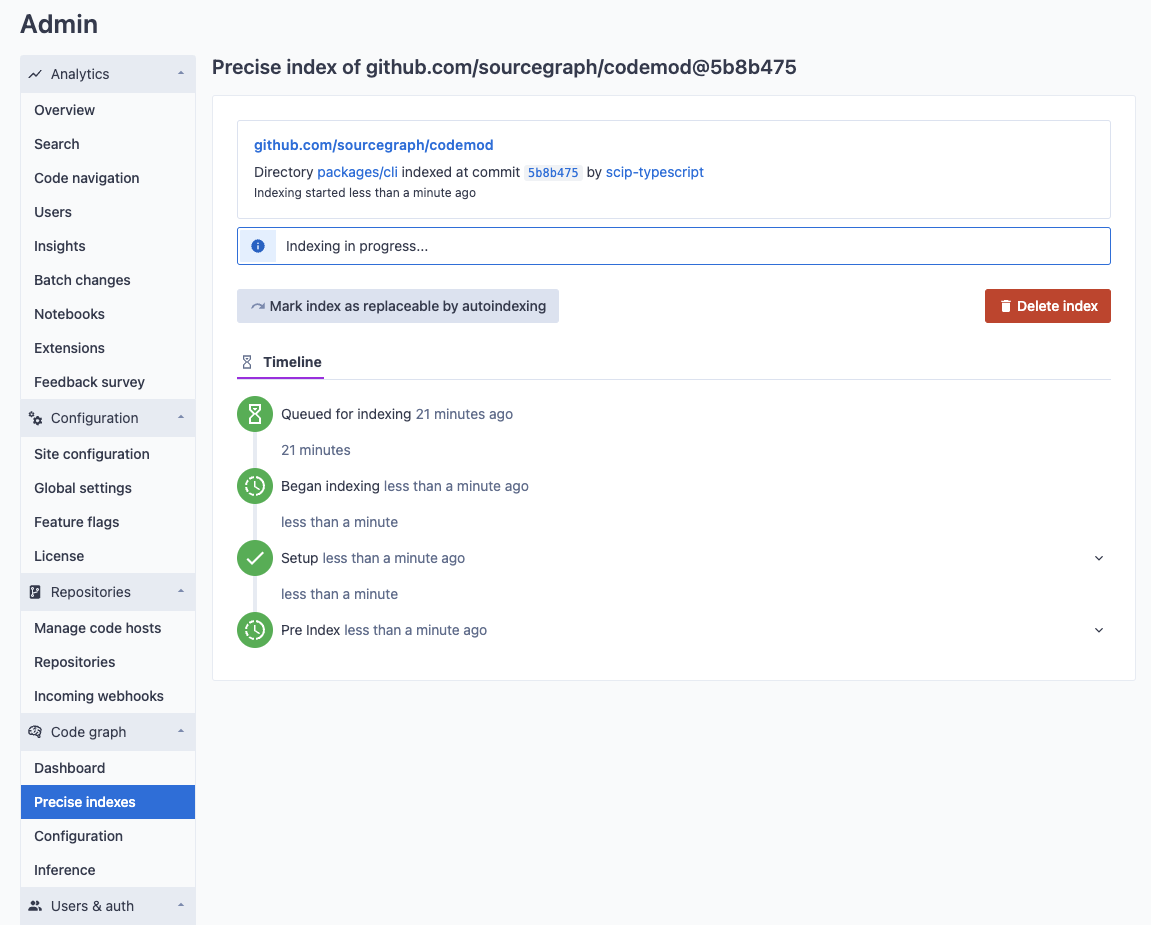
The stdout and stderr of each command run during pre-indexing and indexing steps are viewable as the index job is processed. This information is valuable when troubleshooting a custom index configuration for your repository.
Once the index job completes, a code graph data file has been uploaded to the Sourcegraph instance.