Configure code navigation auto-indexing
Precise code navigation auto-indexing jobs are scheduled based on two fronts of configuration.
The first front selects the set of repositories and commits within those repositories that are candidates for auto-indexing. These candidates are controlled by configuring auto-indexing policies.
The second front determines the set of index jobs that can run over candidate commits. By default, index jobs are inferred from the repository structure's on disk. Index job inference uses heuristics such as the presence or contents of particular files to determine the paths and commands required to index a repository. Alternatively, index job configuration can be supplied explicitly for a repository when the inference heuristics are not powerful enough to create an index job that produces the correct results. This might be necessary for projects that have non-standard or complex dependency resolution or pre-compilation steps, for example.
Configure auto-indexing policies
This guide shows how to configure policies to control the scheduling of precise code navigation indexing jobs. Indexing jobs produce a code graph data index and uploads it to your Sourcegraph instance for use with code navigation.
Each policy has a number of configurable options, including:
- The set of Git branches or tags to which the policy applies
- The maximum age of commits that should be indexed (e.g., skip indexing commits made last year)
- For branches, whether or not to consider the tip of the branch only, or all commits contained in that branch
Note that when auto-indexing is enabled, we will also attempt to schedule index jobs for dependencies of repositories which receive an uploaded code graph data index. This helps to ensure that no matter where symbols are defined, you will be able to navigate to its definition and find a relevant set of references as long as your Sourcegraph instance has knowledge of that code.
Precise code navigation indexing jobs are scheduled periodically in the background for each repository matching an indexing policy.
Applying indexing policies globally
Site admins can create indexing policies that apply to all repositories on their Sourcegraph instance. In order to view and edit these policies, navigate to the code graph configuration in the site-admin dashboard.

New policies can also be created to apply to the HEAD of the default branch, or to apply to any arbitrary Git branch or tag pattern. For example, you may want to index release branches for all of your repositories (in this example, branches whose last commit is older than five years of age will not apply).
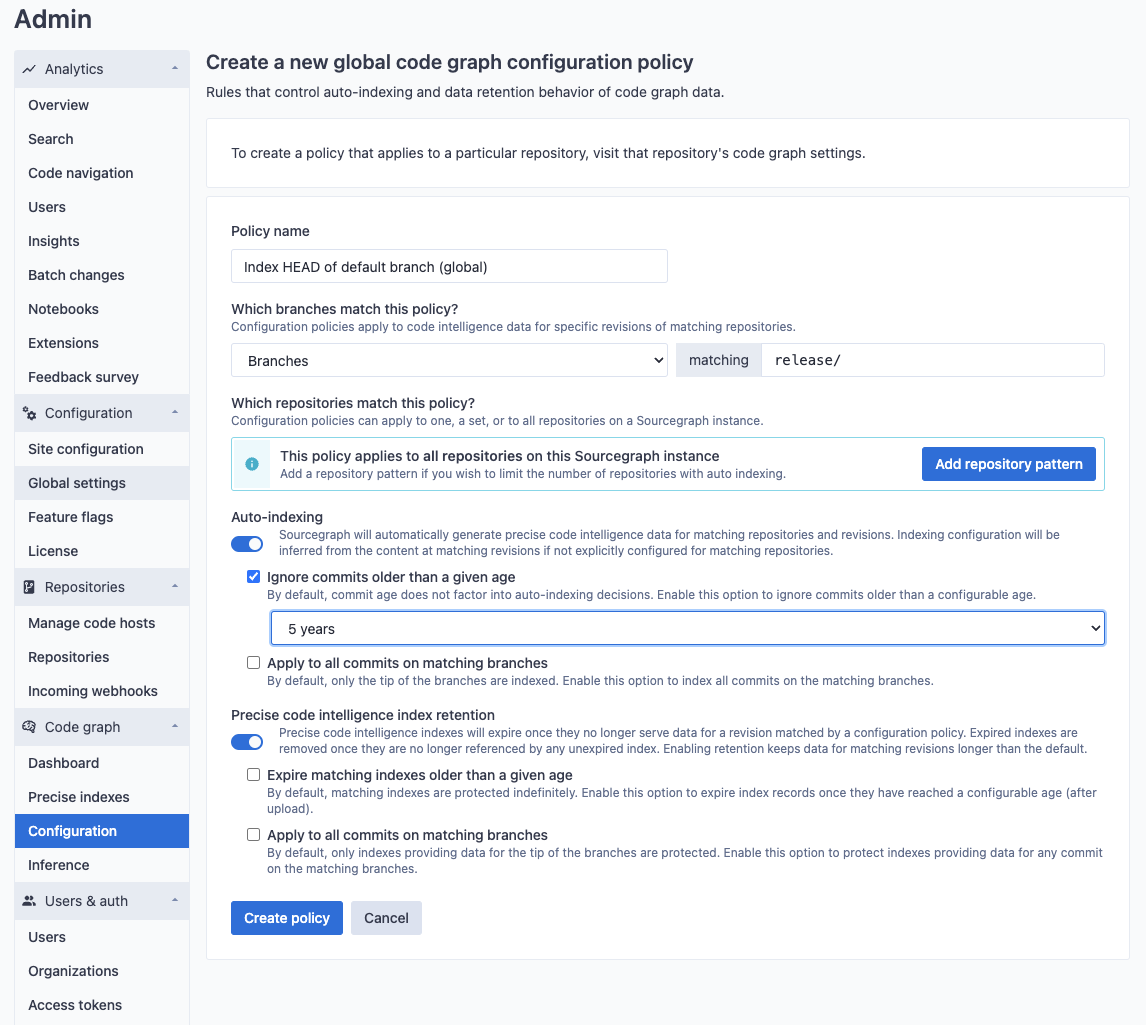

New policies can be created to apply to a set of repositories that are matched by name. For example, you may want to enable indexing for a particular set of repositories (in this example, repositories in the sourcegraph organization).
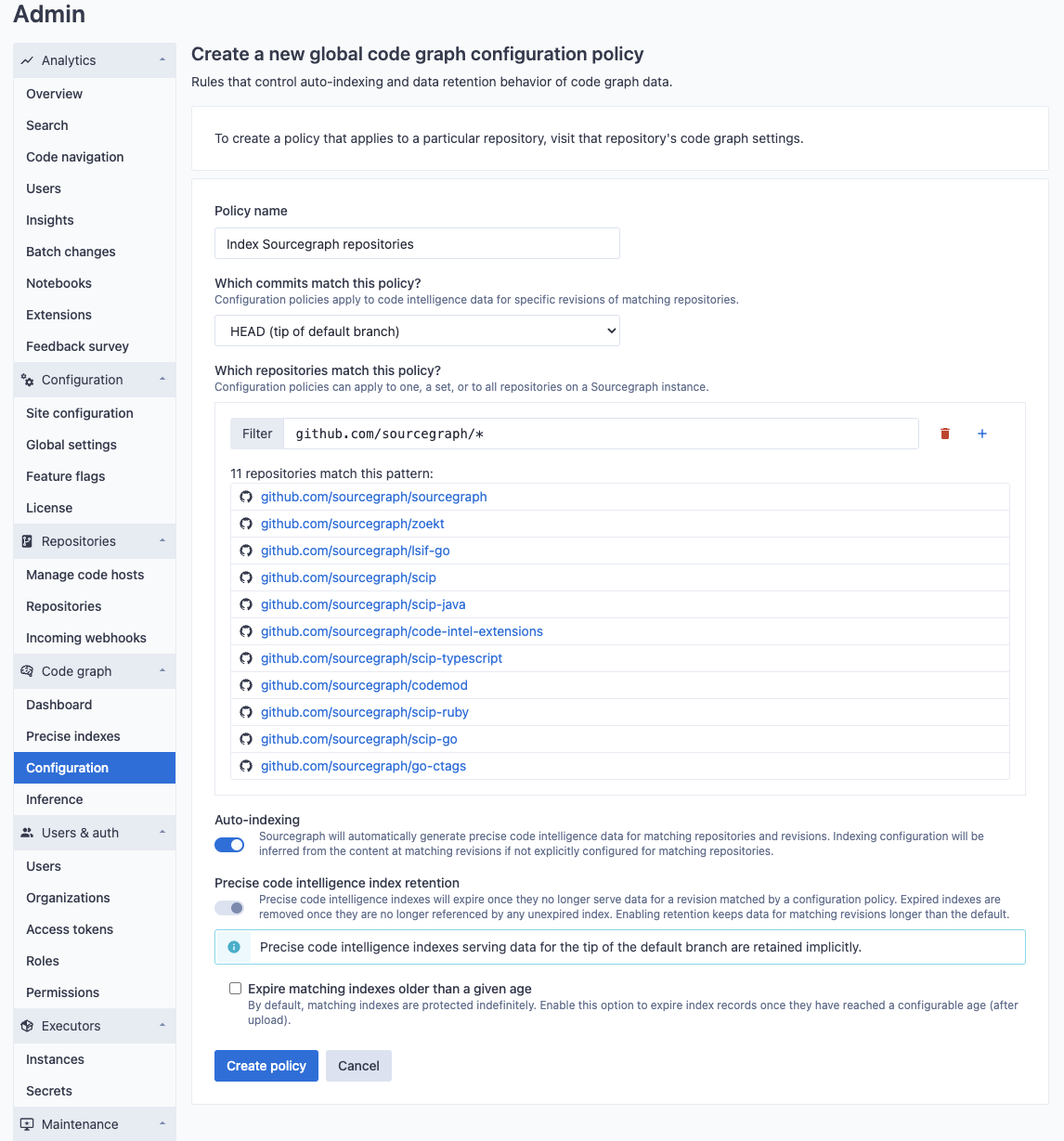
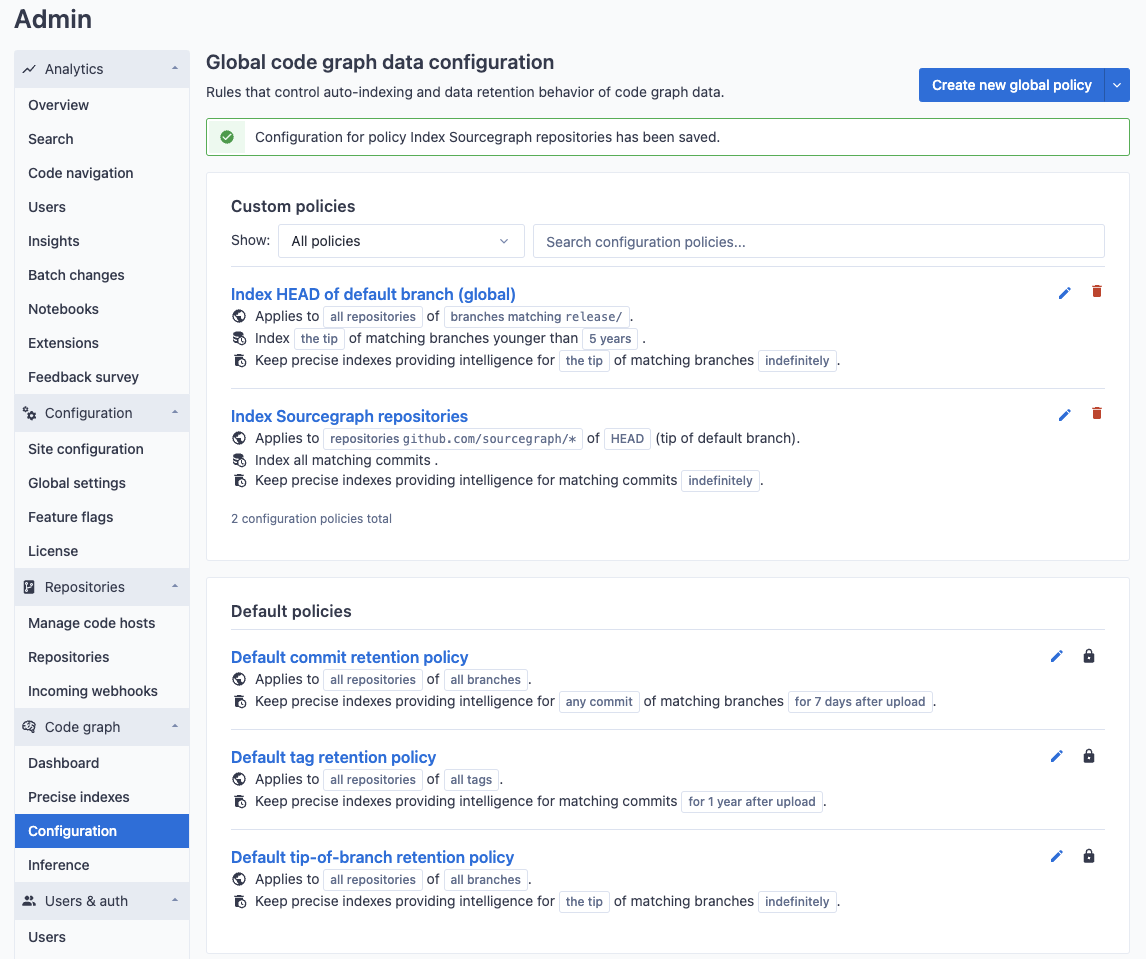
Applying indexing policies to a specific repository
Indexing policies can also be created on a per-repository basis as commit and merge workflows differ wildly from project to project. In order to view and edit repository-specific policies, navigate to the code graph settings in the target repository's index page.
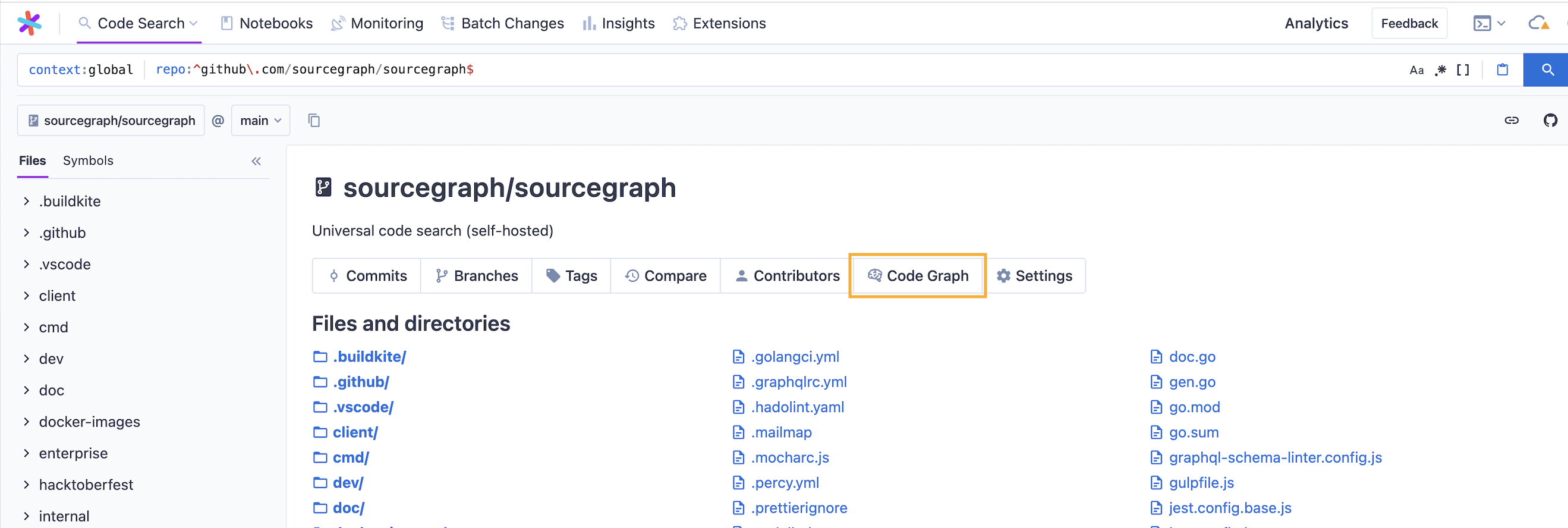
The settings page will show all policies that apply to the given repository, including both repository-specific policies as well as global policies that match the repository.
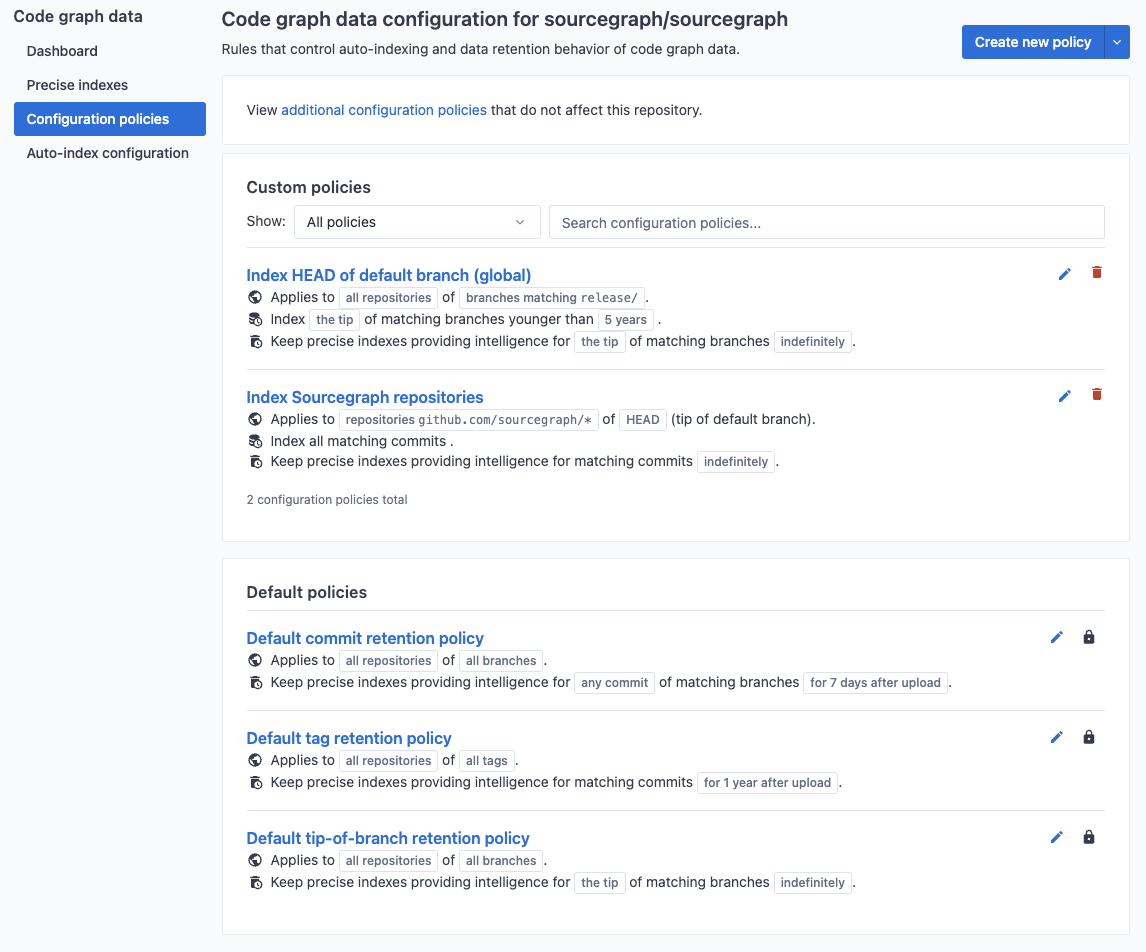
In this example, we create an indexing policy that applies to all versioned tags (those prefixed with v). The Index all version tags policy ensures all commits visible from matching tagged commit will be kept indexed (and not removed due to age).
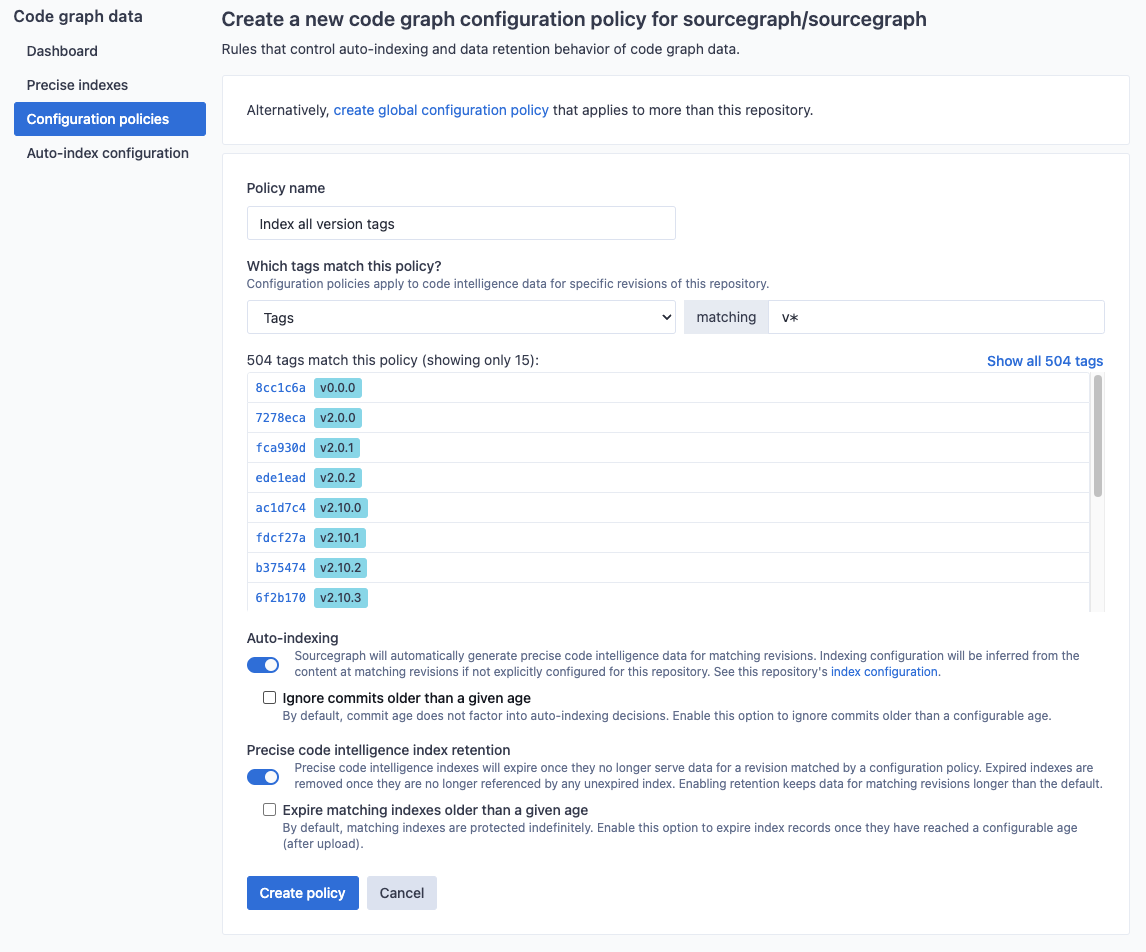
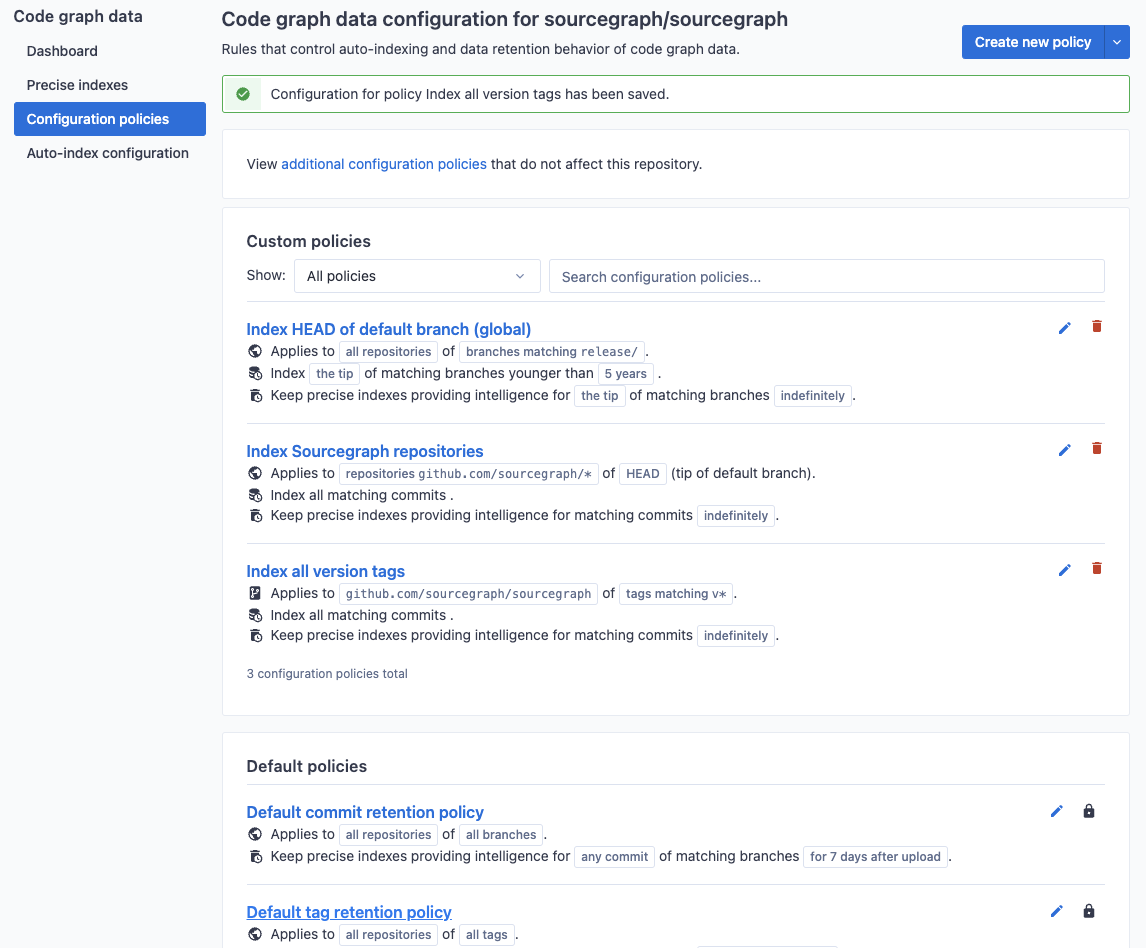
Explicit index job configuration
For projects that have non-standard or complex dependency resolution or pre-compilation steps, inference heuristics might not be powerful enough to create an index job that produces the correct results. In these cases, explicit index job configuration can be supplied to a repository in two ways (listed below in order of decreasing precedence). Both methods of configuration share a common expected schema. See the reference documentation for additional information on the shape and content of the configuration.
-
Configure index jobs by committing a
sourcegraph.yamlfile to the root of the target repository. If you're new to YAML and want a short introduction, see Learn YAML in five minutes. Note that YAML is a strict superset of JSON, therefore the file contents can also be encoded as valid JSON (despite the file extension). -
Configure index jobs via the target repository's code graph settings UI. In order to view and edit the indexing configuration for a repository, navigate to the code graph settings in the target repository's index page.
From there you can view or edit the repository's configuration. We use a superset of JSON that allows for comments and trailing commas. The set of index jobs that would be inferred from the content of the repository (at the current tip of the default branch) can be viewed and may often be useful as a starting point to define more elaborate indexing jobs.
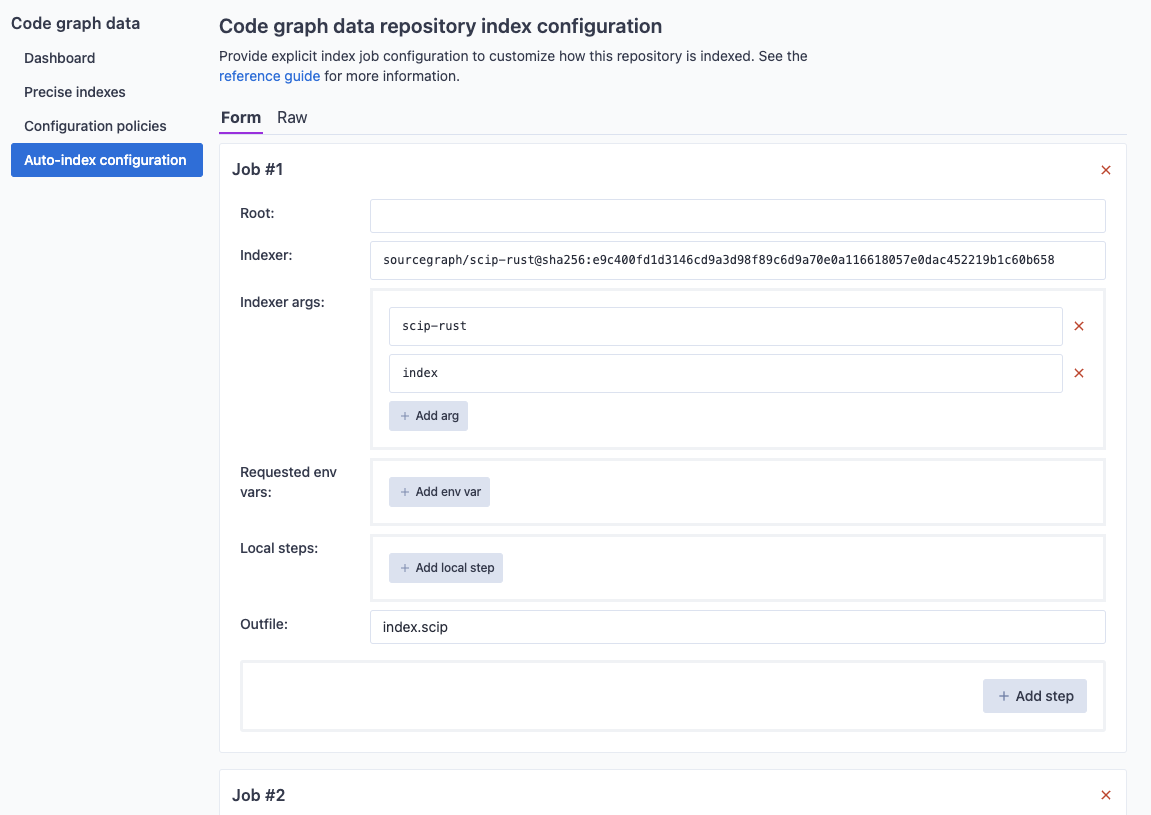
Private repositories and packages configuration
For auto-indexing jobs to be able to build your projects that use private repositories and packages, you need to provide language-specific configuration in the form of Executor secrets.
Go
For Go resolver to access private Git repositories, you need to configure a NETRC_DATA secret with
the following contents:
machine <your-git-host> login <git-user-login> password <github-token-or-password>
Under the hood, this information will be used to write the .netrc file that is respected by Git and Go.
TypeScript/JavaScript
For NPM, you can create a secret named NPM_TOKEN which will be automatically picked up by the indexer.