Worker services
The worker service is a collection of background jobs that run periodically or in response to an external event.
Worker jobs
The following jobs are defined by the worker service.
out-of-band-migrations
This job runs out of band migrations, which perform large data migrations in the background over time instead of synchronously during Sourcegraph instance updates.
codeintel-upload-backfiller
This job periodically checks for records with NULL attributes that need to be backfilled. Often these are values that require data from Git that wasn't (yet) resolvable at the time of a user upload.
codeintel-upload-janitor
This job periodically removes expired and unreachable code navigation data and reconciles data between the frontend and codeintel-db database instances.
codeintel-upload-expirer
This job periodically matches code navigation data against data retention policies.
codeintel-commitgraph-updater
This job periodically updates the set of code graph data indexes that are visible from each relevant commit for a repository. The commit graph for a repository is marked as stale (to be recalculated) after repository updates and code graph data uploads and updated asynchronously by this job.
Scaling notes: Throughput of this job can be effectively increased by increasing the number of workers running this job type. See the horizontal scaling second below for additional details.
codeintel-autoindexing-scheduler
This job periodically checks for repositories that can be auto-indexed and queues indexing jobs for a remote executor instance to perform. Read how to enable and configure auto-indexing.
codeintel-autoindexing-summary-builder
This job periodically checks for auto-indexability on repositories in the background. This is used to populate the global code intelligence dashboard.
codeintel-autoindexing-dependency-scheduler
This job periodically checks for dependency packages that can be auto-indexed and queues indexing jobs for a remote executor instance to perform. Read how to enable and configure auto-indexing.
codeintel-metrics-reporter
This job periodically emits metrics to be scraped by Prometheus about code intelligence background jobs.
codeintel-policies-repository-matcher
This job periodically updates an index of policy repository patterns to matching repository names.
codeintel-crates-syncer
This job periodically updates the crates.io packages on the instance by syncing the crates.io index.
codeintel-ranking-file-reference-counter
This job periodically calculates a global reference count of text documents within a repo from other text documents on the instance.
codeintel-uploadstore-expirer
This job periodically compares index records against retention policies and marks them as expired if they are unprotected.
codeintel-package-filter-applicator
This job periodically updates the blocked status of package repo references and versions when package repo fitlers are updated or deleted.
insights-job
This job contains most of the background processes for Code Insights. These processes periodically run and execute different tasks for Code Insights:
- Insight enqueuer
- Insight backfiller
- Insight license checker
- Insight backfill checker
- Data clean up jobs
- Retention job enqueuer
insights-query-runner-job
This job is responsible for processing and running record and snapshot points for Code Insights. Such points are filled by running global searches. This job was split from the other Code Insights background processes so that it could benefit from horizontal scaling.
insights-data-retention-job
This job is responsible for periodically archiving code insights data points that are beyond the maximum sample size as specified by the site config setting insights.maximumSampleSize. It dequeues jobs which are enqueued from the insights-job worker in the retention job enqueuer routine. Data will only be archived if the experimental setting insightsDataRetention is enabled.
webhook-log-janitor
This job periodically removes stale log entries for incoming webhooks.
executors-janitor
This job periodically removes old heartbeat records for inactive executor instances.
codemonitors-job
This job contains all the background processes for Code Monitors:
- Periodically execute searches
- Execute actions triggered by searches
- Cleanup of old execution logs
batches-janitor
This job runs the following cleanup tasks related to Batch Changes in the background:
- Metrics exporter for executors
- Changeset reconciler worker resetter
- Bulk operation worker resetter
- Batch spec workspace execution resetter
- Batch spec resolution worker resetter
- Changeset spec expirer
- Execution cache entry cleaner
batches-scheduler
This job runs the Batch Changes changeset scheduler for rollout windows.
batches-reconciler
This job runs the changeset reconciler that publishes, modifies and closes changesets on the code host.
batches-bulk-processor
This job executes the bulk operations in the background.
batches-workspace-resolver
This job runs the workspace resolutions for batch specs. Used for batch changes that are running server-side.
gitserver-metrics
This job runs queries against the database pertaining to generate gitserver metrics. These queries are generally expensive to run and do not need to be run per-instance of gitserver so the worker allows them to only be run once per scrape.
outbound-webhook-sender
This job dispatches HTTP requests for outbound webhooks and periodically removes old logs entries for them.
repo-statistics-compactor
This job periodically cleans up the repo_statistics and gitserver_repos_statistics tables by rolling up all rows into a single row.
repo-statistics-resetter
This job cleans up and recreates the repo_statistics/gitserver_repos_statistics table.
Attention: it requires exclusive locks on the repo and gitserver_repos, which means it might take 3-4 minutes to run if the instance is very busy.
It's only running on Sunday mornings at ~2am UTC.
record-encrypter
This job bulk encrypts existing data in the database when an encryption key is introduced, and decrypts it when instructed to do. See encryption for additional details.
zoekt-repos-updater
This job periodically fetches the list of indexed repositories from Zoekt shards and updates the indexing status accordingly in the zoekt_repos table.
auth-sourcegraph-operator-cleaner
This job periodically cleans up the Sourcegraph Operator user accounts on the instance. It hard deletes expired Sourcegraph Operator user accounts based on the configured lifecycle duration every minute. It skips users that have external accounts connected other than service type sourcegraph-operator (i.e. a special case handling for "sourcegraph.sourcegraph.com").
license-check
This job starts the periodic license check that ensures the Sourcegraph instance is in compliance with its license and that the license is still valid. If the license is not valid anymore, features will be disabled and a warning banner will be shown.
Scaling notes: There must always be just a single instance of license-check worker. Scaling this worker horizontally would result in unexpected behavior. See the horizontal scaling second below for additional details.
rate-limit-config
This job periodically takes the rate limit configurations in the database, and copies them into Redis, where our rate limiters will start using them.
Deploying workers
By default, all of the jobs listed above are registered to a single instance of the worker service. For Sourcegraph instances operating over large data (e.g., a high number of repositories, large monorepos, high commit frequency, or regular code graph data uploads), a single worker instance may experience low throughput or stability issues.
There are several strategies for improving throughput and stability of the worker service:
1. Scale vertically
Scale the worker service vertically by increasing resources for the service container. Increase the CPU allocation when the service appears CPU-bound and increase the memory allocation when the service consistently uses the majority of its memory allocation or suffers from out-of-memory errors.
The CPU and memory usage of each instance can be viewed in the worker service's Grafana dashboard. Out-of-memory errors will see a sudden rise in memory usage for a particular instance, followed immediately by a new instance coming online.


2. Scale horizontally
Scale the worker service horizontally by increasing the number of running services.
This is an effective strategy for some job types but not others. For example, the codeintel-commitgraph job running over two instances will be able to process the commit graph for two repositories concurrently. However, the codeintel-janitor job mostly issues SQL deletes to the database and is less likely to see a major benefit by increasing the number of containers. Also note that scaling in this manner will not reduce CPU or memory contention between jobs on the same container.
To determine if this strategy is effective for a particular job type, refer to scaling notes for that job in the section above.
3. Split jobs and scale independently
Scale the worker instance by splitting jobs by type into separate functional instances of the worker service. Each resulting instance can be scaled independently as described above.
The jobs that a worker instance runs are be controlled via two environment variables: WORKER_JOB_ALLOWLIST and WORKER_JOB_BLOCKLIST. Each environment variable is a comma-separated list of job names (specified in the section above). A job will run on a worker instance if that job is explicitly listed in the allow list, or the allow list is "all" (the default value), and is not explicitly listed in the block list.
Example
Consider a hypothetical Sourcegraph instance that has a number of repositories with large commit graphs. In this instance, the codeintel-commitgraph job under-performs and several repository commit graphs stay stale for longer than expected before being recalculated. As this job is also heavily memory-bound, we split it into a separate instance (co-located with no other jobs) and increase its memory and replica count.
| Name | Allow list | Block list | CPU | Memory | Replicas |
|---|---|---|---|---|---|
| Worker 1 | all |
codeintel-commitgraph |
2 | 4G | 1 |
| Worker 2 | codeintel-commitgraph |
2 | 8G | 3 |
Now, the codeintel-commitgraph job can process three repository commit graphs concurrently and have enough dedicated memory to ensure that the jobs succeed for the instance's current scale.
Observability
The worker service's Grafana dashboard is configured to show the number of instances processing each job by type and alert if there is no instance processing a particular type of job.
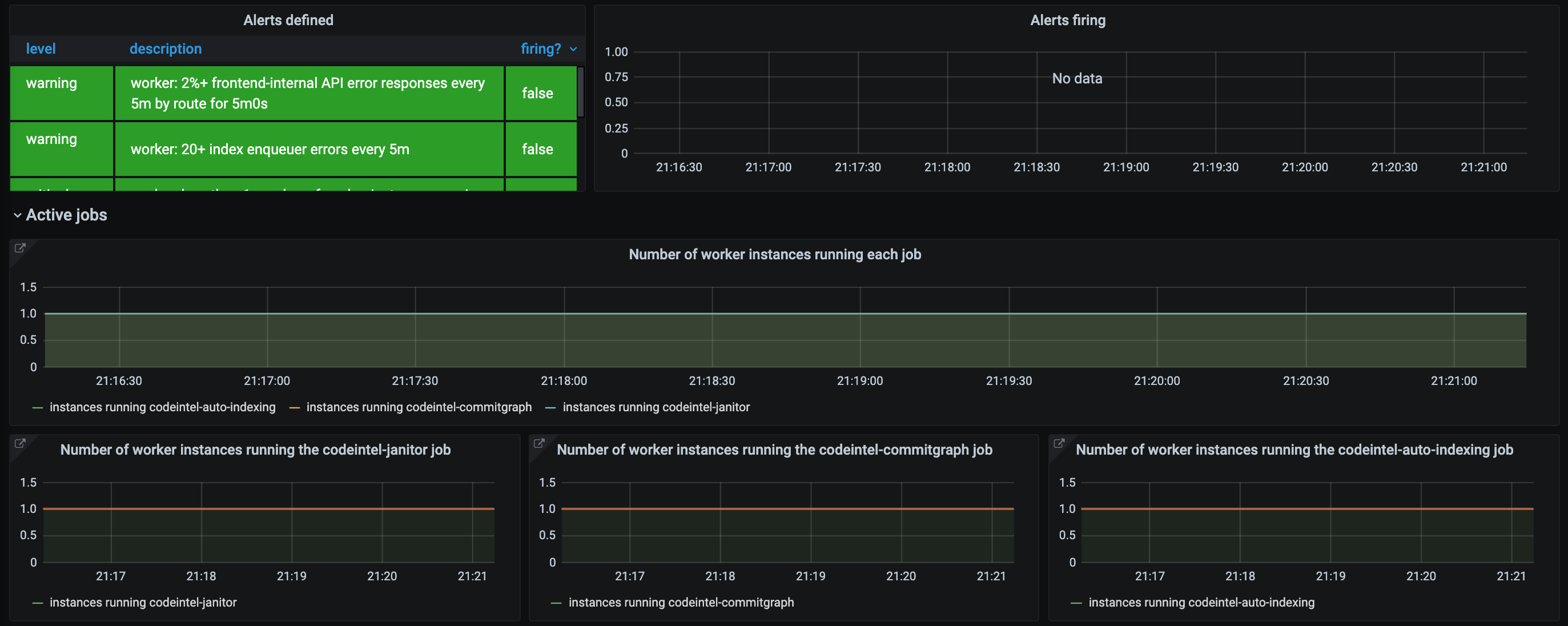
Here is a snapshot of a healthy dashboard, where each job is run by a single worker instance.
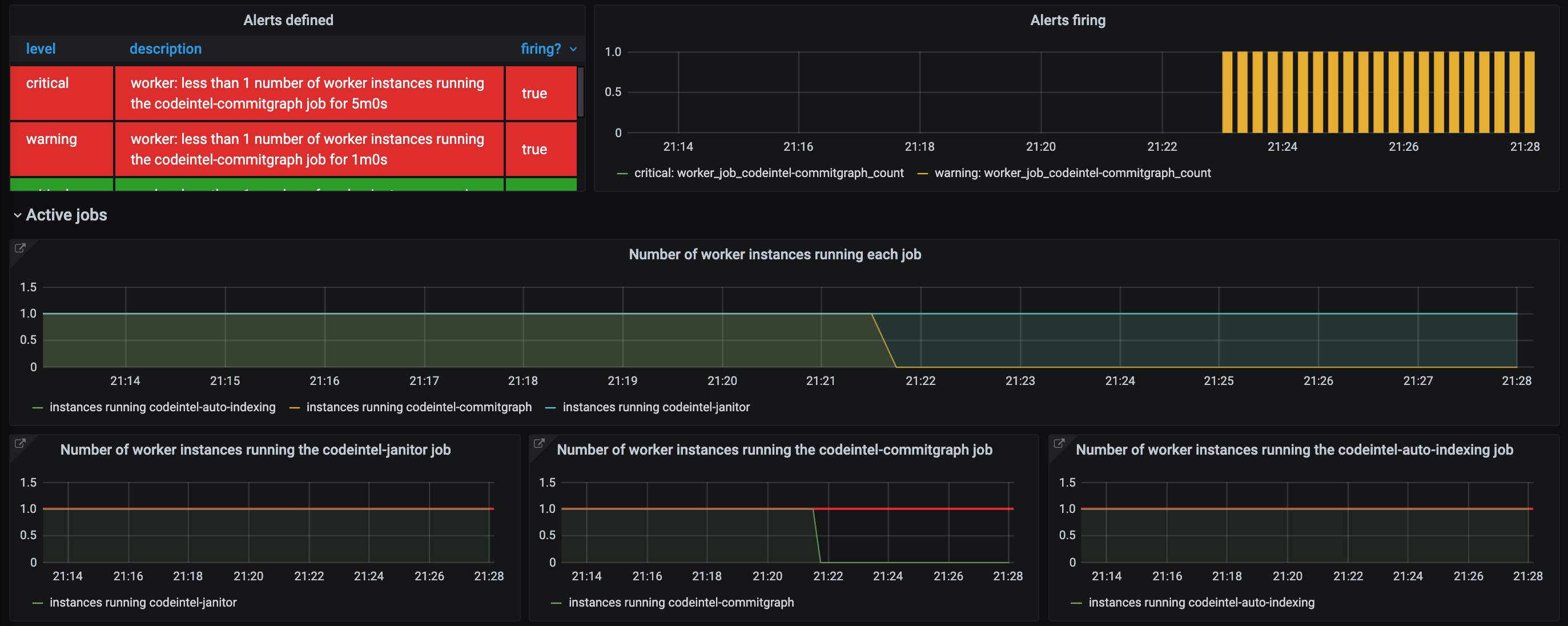
Here is a snapshot of an unhealthy dashboard, where no active instance is running the codeintel-commitgraph job (for over five minutes to allow for non-noisy reconfiguration).