Configure code graph data retention policies
Configure the retention policies of your code graph data to prevent old data from taking up valuable space in the database.
As code graph data ages, it gets less and less relevant. Users tend to need code navigation on newer commits, tagged commits, and in branches. The data providing intelligence for an old commit on the main development branch is unlikely to be used and only takes up valuable space in the database.
Each policy has several configurable options, including:
- The set of Git branches or tags to which the policy applies.
- How long to keep the associated code graph data.
- For branches, whether or not to consider the tip of the branch only or all commits contained in that branch.
Note that Sourcegraph tracks cross-repository dependencies and will not delete any data that is referenced by another code graph data index. This means that code graph data for dependencies pinned to older versions or dependencies that have reached a steady state and no longer receive frequent updates will not be deleted.
All upload records will be periodically compared against global data retention policies and their target repository's data retention policies. Uploads on the tip of the default branch for a repository will never expire, regardless of age.
Applying data retention policies globally
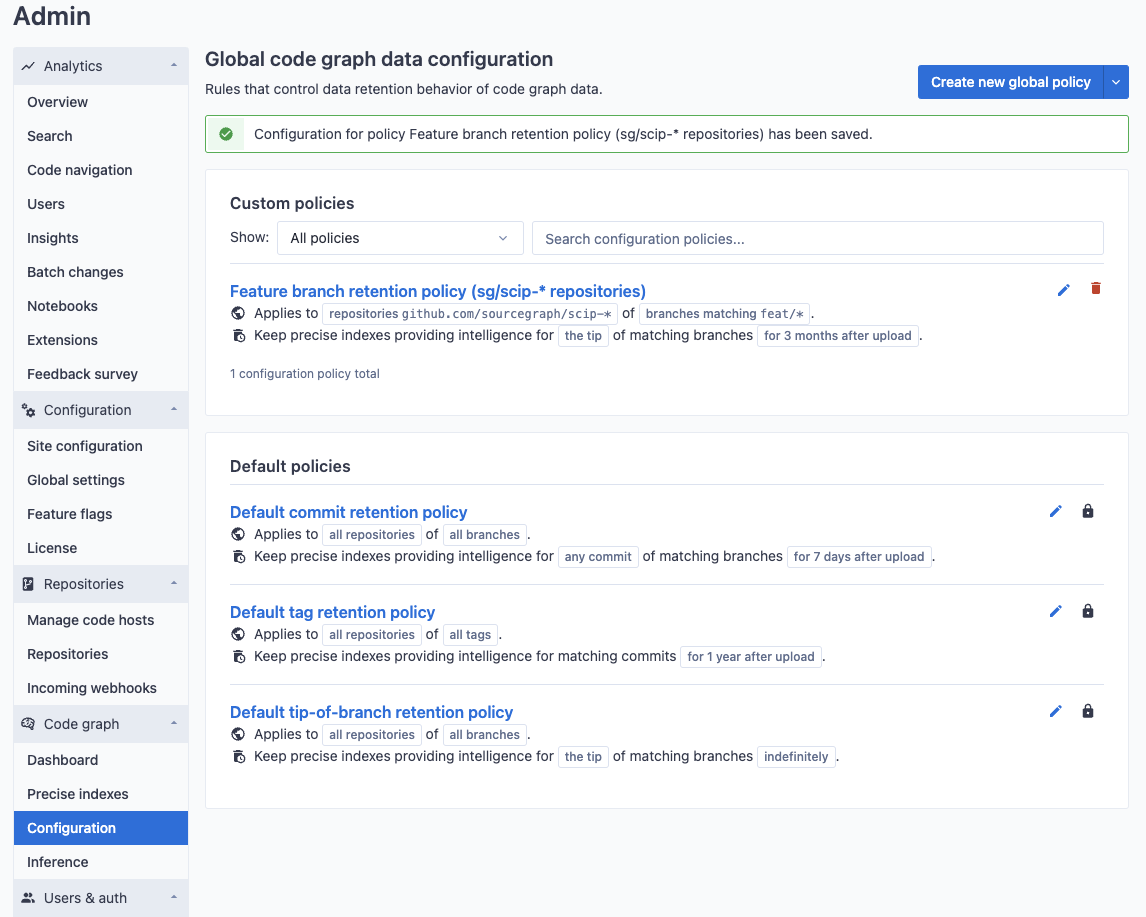
Site admins can create data retention policies that are applied to all repositories on your Sourcegraph instance. To view and edit these policies, navigate to the code graph configuration in the site-admin dashboard.
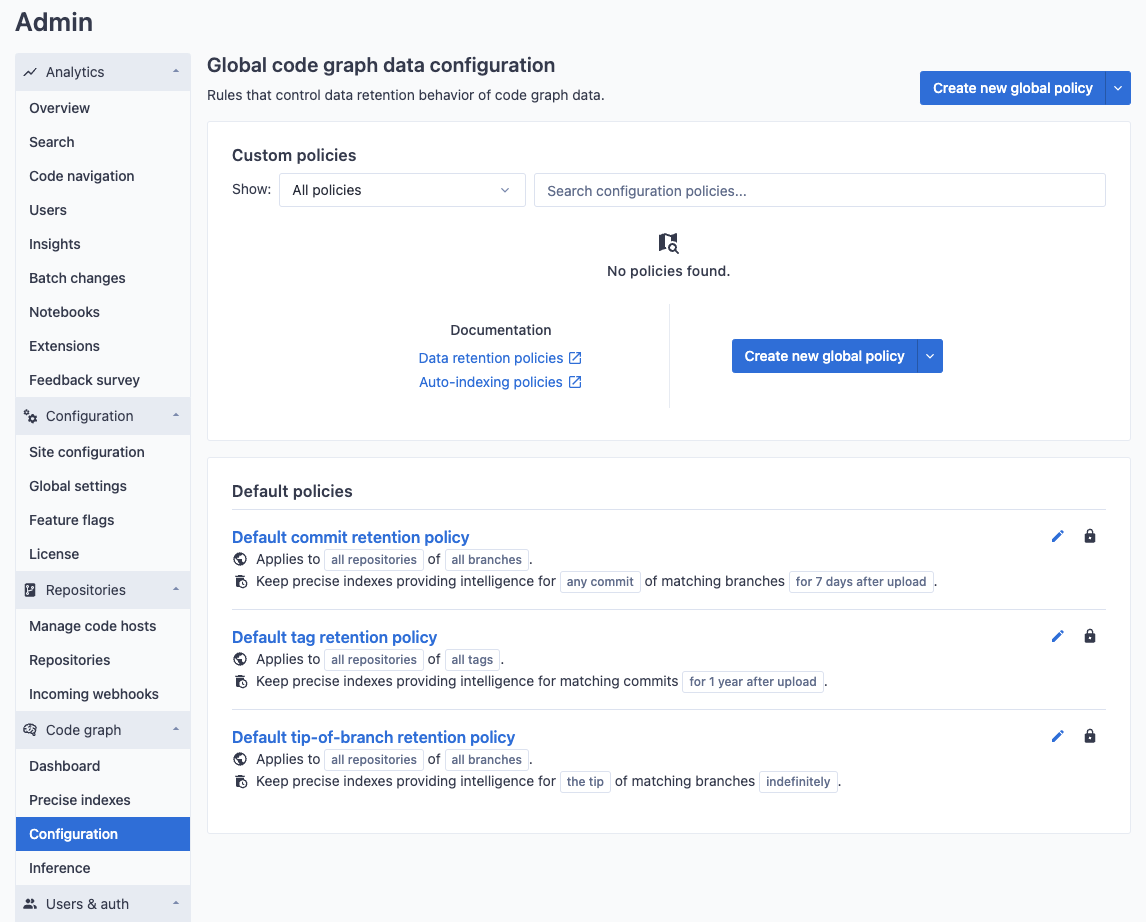
By default, there are three protected policies that cannot be deleted or disabled. These policies refer to all tagged commits (associated data being kept for one year by default), the tip of all branches (associated data being kept for three months by default), and the HEAD of the default branch (associated data being kept forever by default) for all repositories. Protected policies cannot be deleted or disabled, but the retention length can be modified to suit your instance's usage patterns.
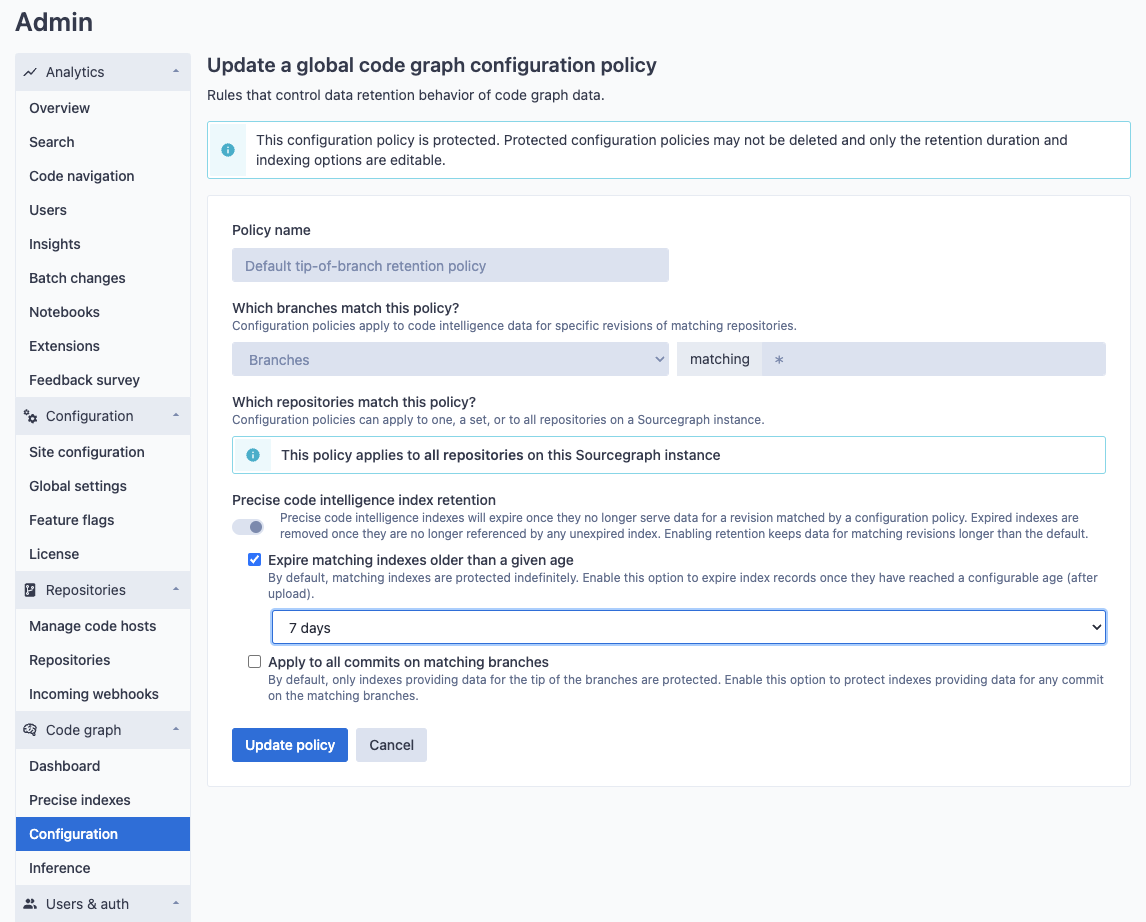
New policies can also be created to apply to the HEAD of the default branch or to apply to any arbitrary Git branch or tag pattern. For example, you may want to never expire data for any major version tags in your organization.
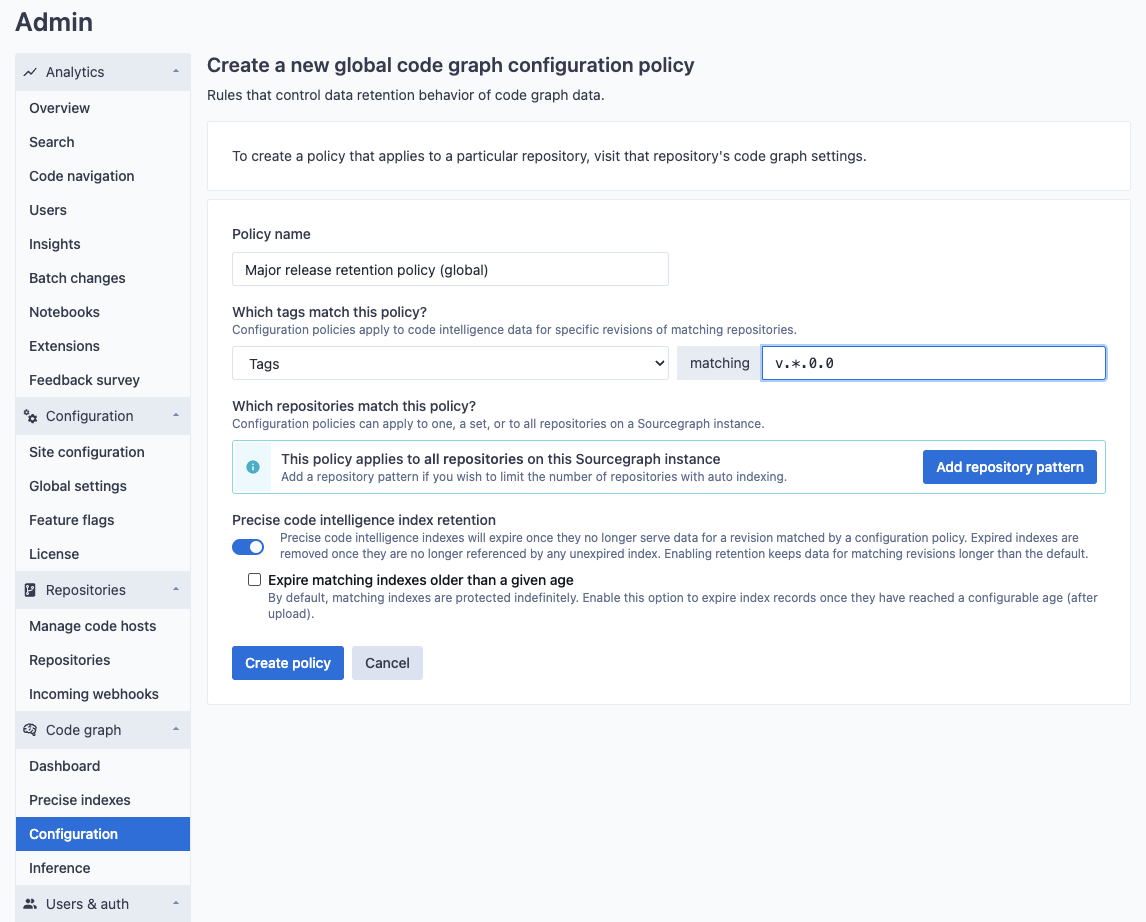
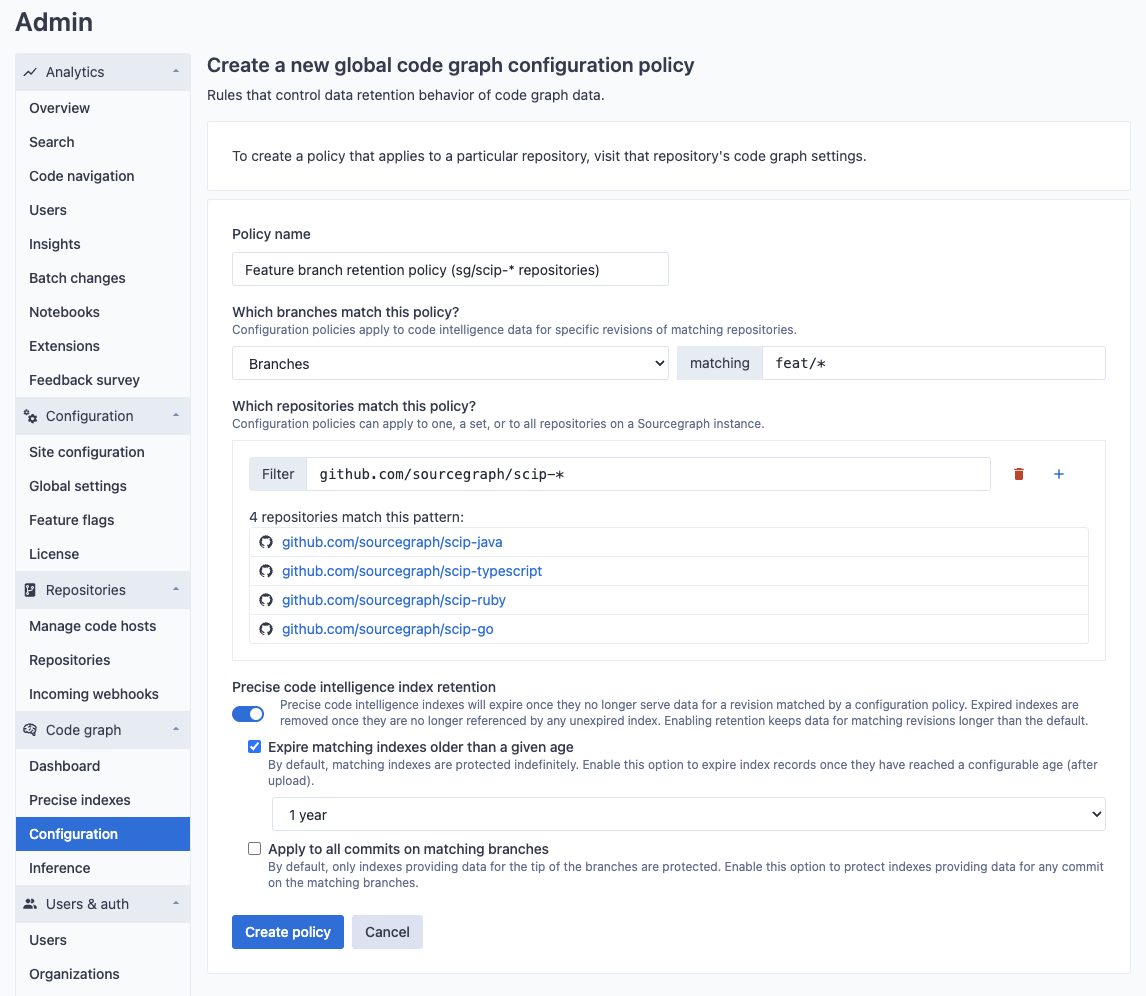
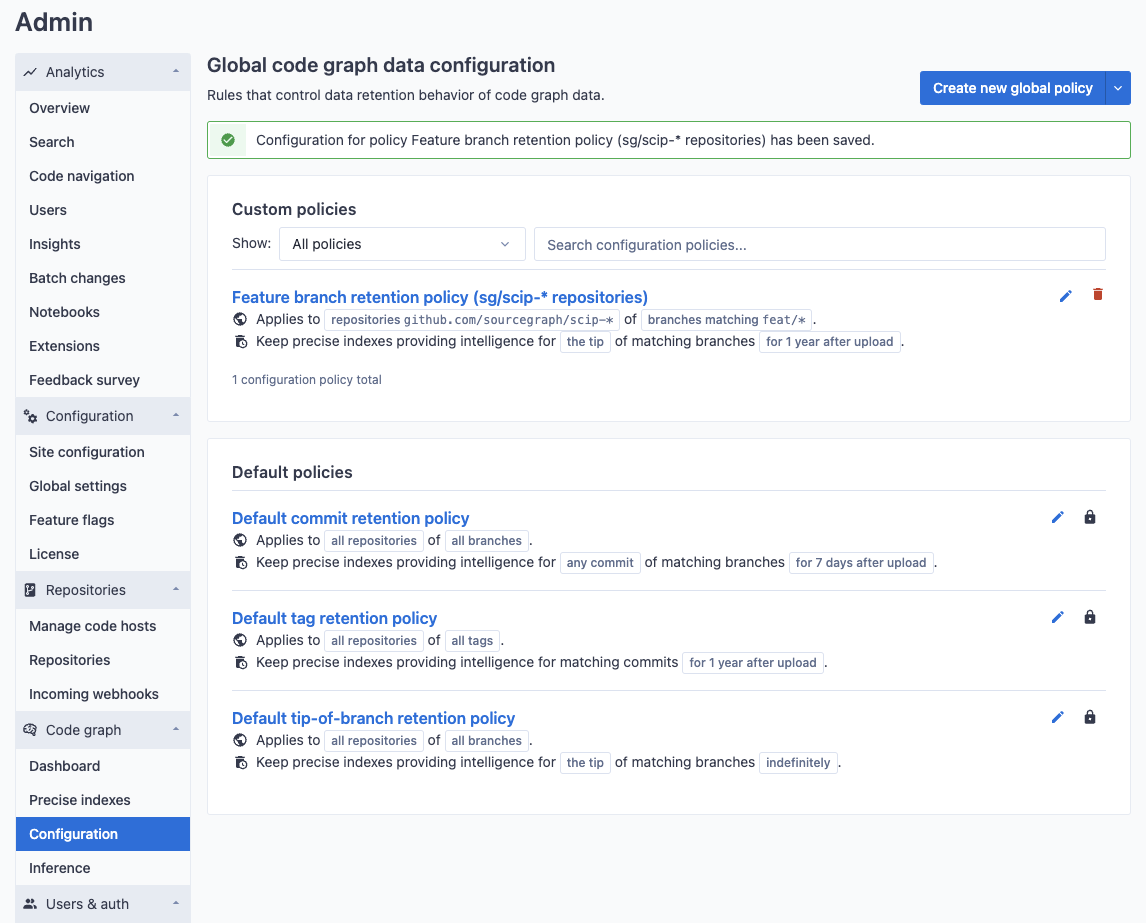
New policies can be created to apply to a set of repositories that are matched by name. For example, you may want to change the duration retention on branches that exist within a particular set of repositories (in this example, repositories in the same organization matching scip-*).
Applying data retention policies to a specific repository
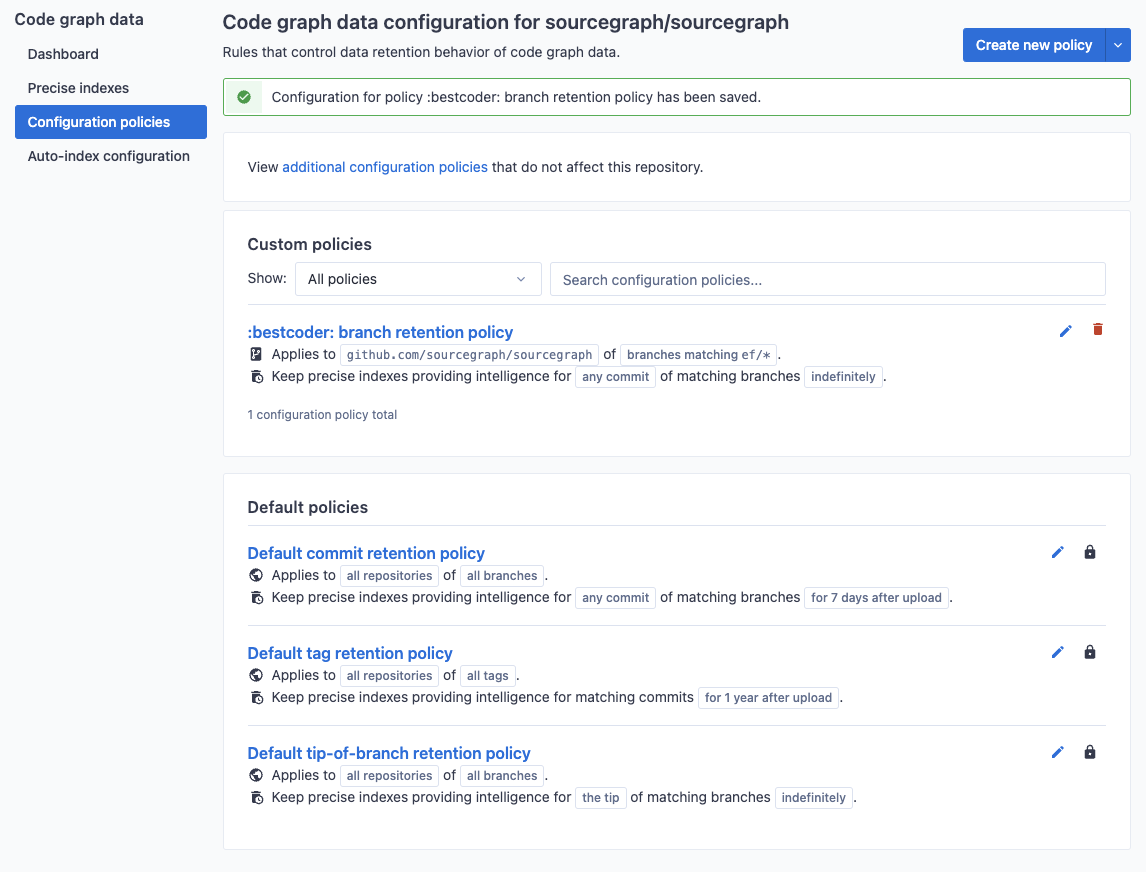
Data retention policies can also be created on a per-repository basis as commit and merge workflows differ widely from project to project. To view and edit repository-specific policies, navigate to the code graph settings on the target repository's index page.
The settings page will show all policies that apply to the given repository, including repository-specific policies and global policies.
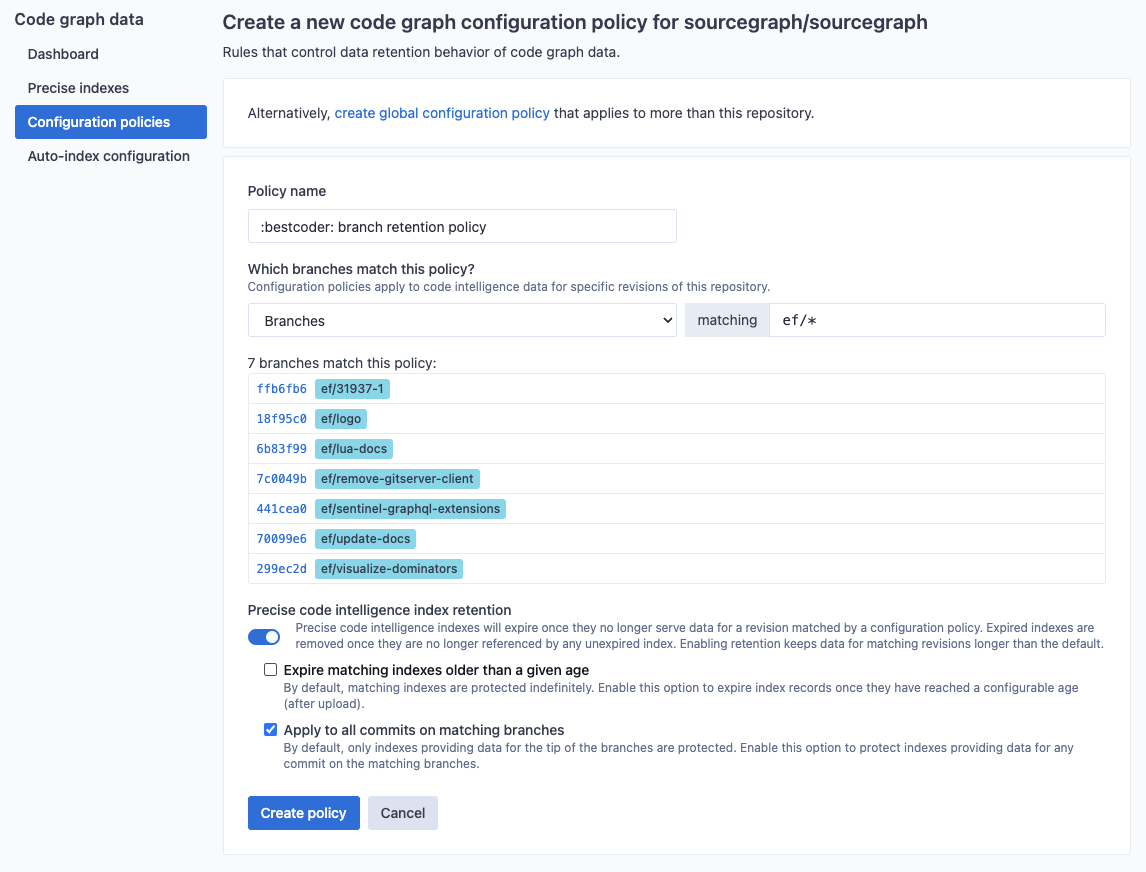
In this example, we create the :bestcoder: branch retention policy that ensures all commits visible to the tip of any branch matching the pattern ef/* will not be removed regardless of age.