Calculating intelligent search ranking
Sourcegraph 5.1+
If you are uploading SCIP data to support precise code navigation, then Sourcegraph can perform a global analysis over all SCIP indexed code to build a file reference graph. The relative number of references to two files can then be used to rank search results so that more highly referenced files come earlier in the result set.
Enable the background jobs
To enable a period job that will calculate global ranking scores, add the following elements to the instance's site configuration.
{ "codeIntelRanking.documentReferenceCountsEnabled": true, "codeIntelRanking.documentReferenceCountsCronExpression": "@weekly", "codeIntelRanking.documentReferenceCountsGraphKey": "dev" }
Enabling the document reference count feature will begin two background jobs that run in the worker container:
- A SCIP exporter, which maintains a view of the relevant SCIP data for analysis, and
- A map/reduce-like job that counts the number of references to a file across all indexed code.
When the exporter job first starts, all SCIP indexes will need to be initially exported. Once most visible indexes have been initially exported, the exporter will make incremental adjustments to this view to ensure it always reflects reality. SCIP indexes that are no longer visible are removed from this view, and new processed SCIP indexes becoming visible will be added.
When the map-reduce-like job starts, it will use whatever data is currently visible in the exported view. Until the initial export has completed, there will be ranking scores missing for some repositories with SCIP indexes once the calculation completes. The cron expression can be supplied to control how frequently and when to begin a new ranking calculation. This job is performed periodically, and its cadence can be controlled by the cron expression setting. This setting's value is parsed by Hashicorp's cronexpr library. Some sample valid expressions include:
@weekly, the default, means midnight in the morning of each Sunday0 0 * * FRImeans midnight every Friday0 0 * * *means midnight every day0 */6 * * *means every six hours*/5 * * * *means every five minutes
The default is likely to be correct for most instances, as initial ranking scores for files are unlikely to decay into inaccurate scores quickly (saving very large refactors or code movement).
The graph key of the ranking job can be changed at any time to abandon any progress made on the current set of ranking scores and begin fresh (including the SCIP data export). This value will not need to be changed under normal operation.
Check background job status and progress
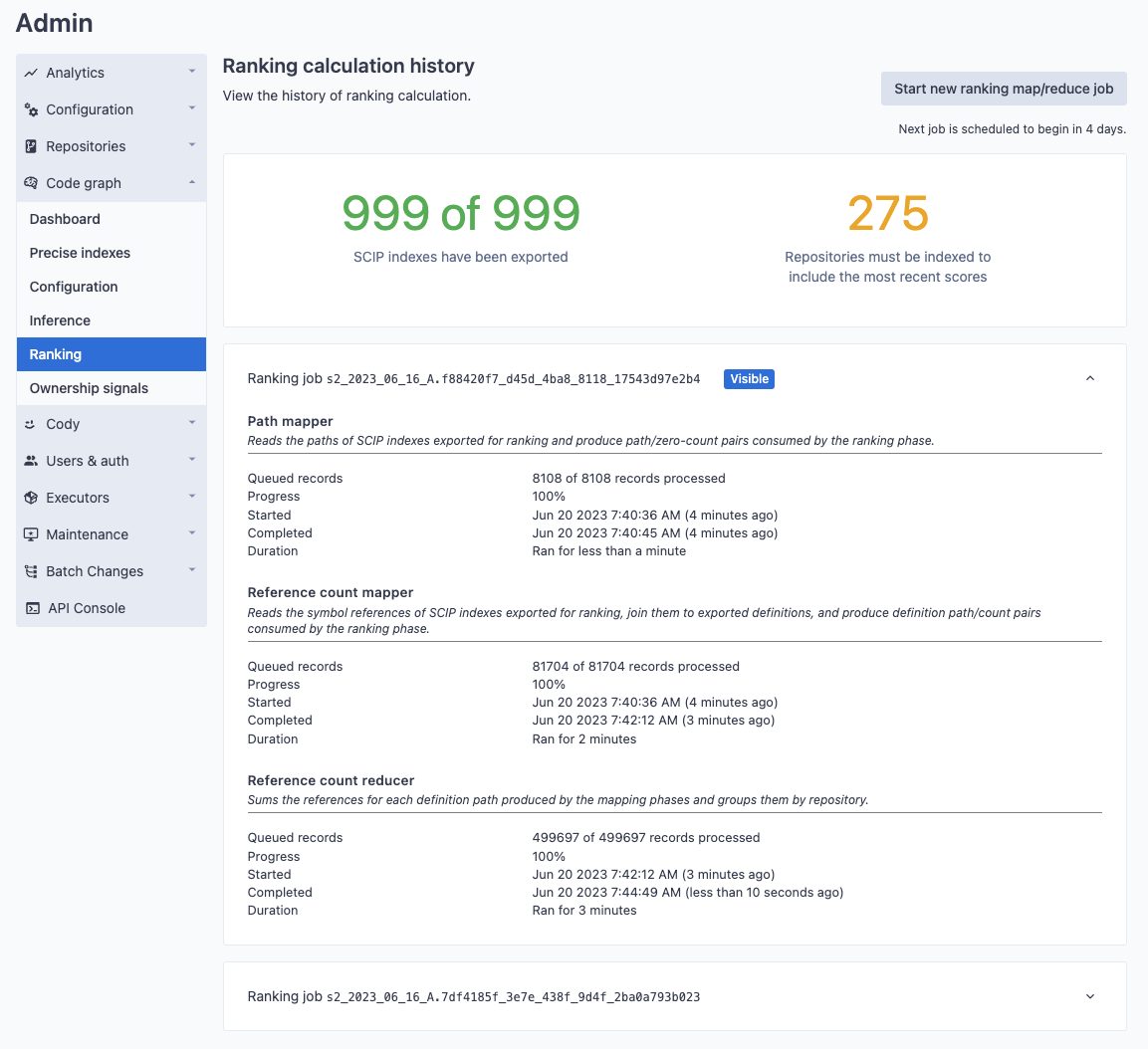
The progress of ranking exports and calculations can be viewed in the UI under Site Admin > Code graph > Ranking.
After initially enabling the background jobs, there will be a low but rising count of exported SCIP indexes. Ranking jobs may be queued and (quickly) finish, but they will only contain data that was exported at the time the job began. Once the majority of SCIP indexes are exported, file ranks will become non-partial.
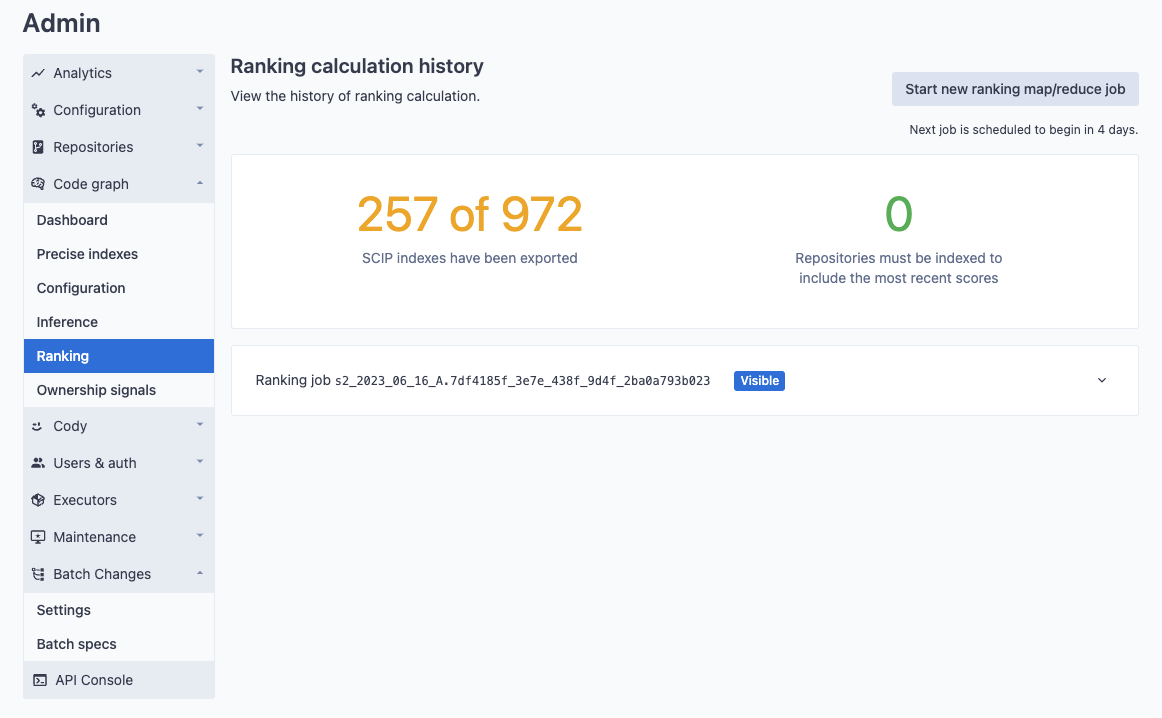
A ranking job will start based on the cadence setting described in the previous section, but a new job can also be started at any time via the UI by pressing the Start new ranking map/reduce job. This may be especially useful when initially enabling the feature when the initial export completes at the front half of a weekly scheduled job.
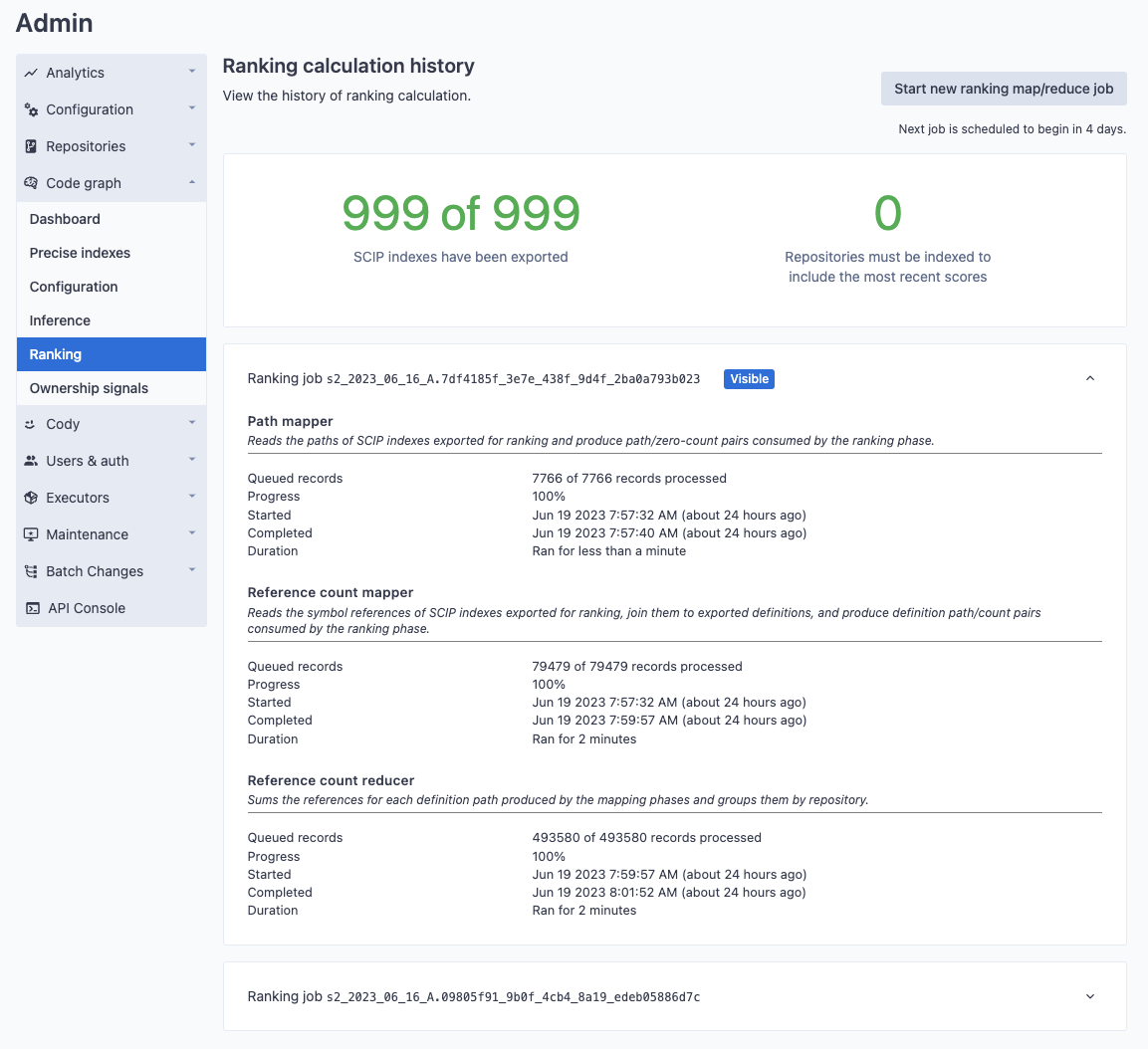
The ranking calculation will perform three steps:
- Path mapper emits a zero count for every path in the exported data (so that paths with no inbound references are still in the output)
- Reference count mapper emits a count for every reference to a symbol defined in each file
- Reference count reducer sums the final reference counts for each document path
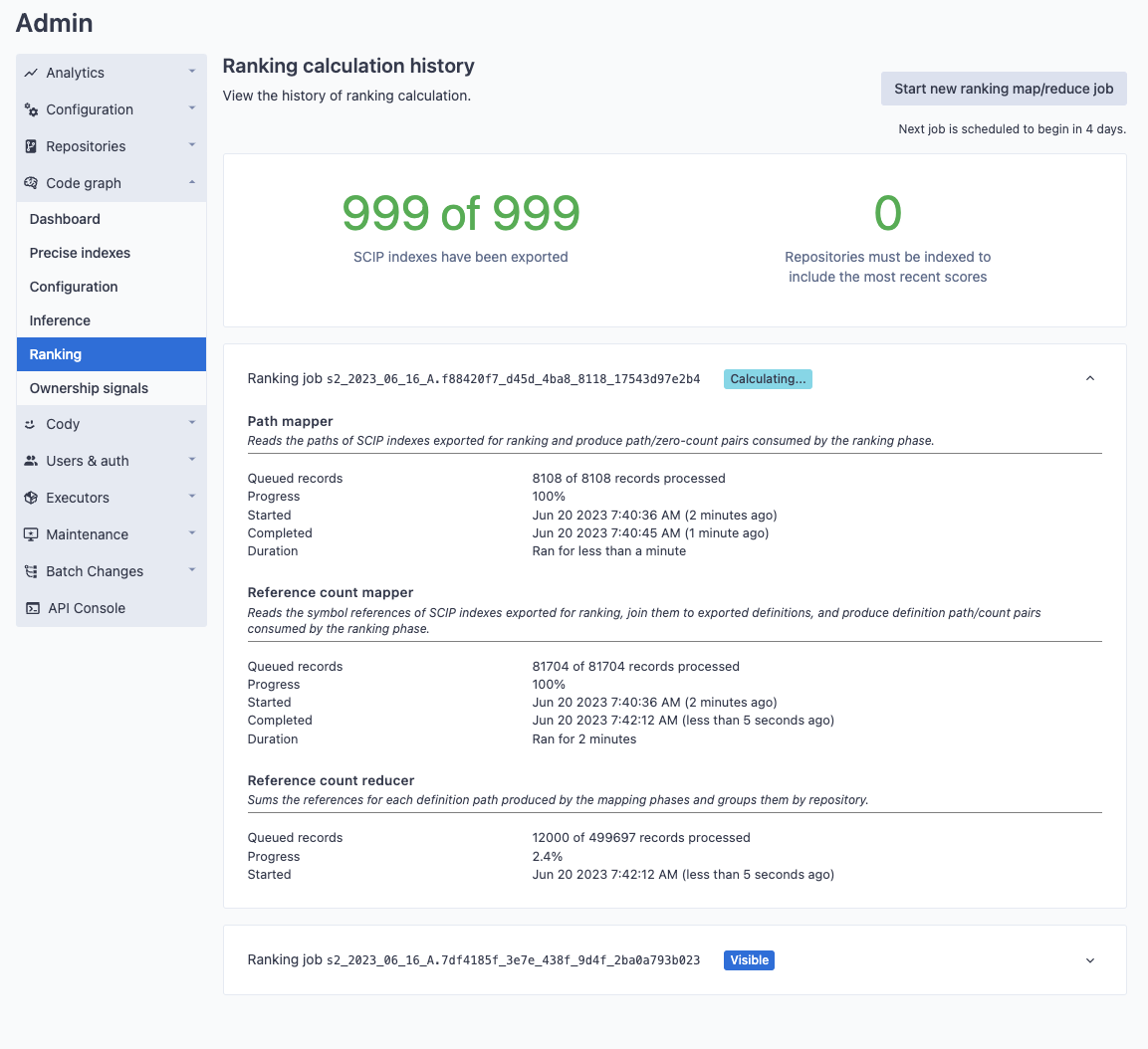
Once the reducer step has completed, the new reference count ranks become visible to consumers all at once. Zoekt will see that new ranks are available for the affected repositories and schedule them for re-indexing (over time, in a manner that does not choke the indexserver) so that new ranks influence the shard ordering.