Worker services
The worker service is a collection of background jobs that run periodically or in response to an external event.
Worker jobs
The following jobs are defined by the worker service.
out-of-band-migrations
This job runs out of band migrations, which perform large data migrations in the background over time instead of synchronously during Sourcegraph instance updates.
codeintel-commitgraph
This job periodically updates the set of precise code intelligence indexes that are visible from each relevant commit for a repository. The commit graph for a repository is marked as stale (to be recalculated) after repository updates and precise code intelligence uploads and updated asynchronously by this job.
Scaling notes: Throughput of this job can be effectively increased by increasing the number of workers running this job type. See the horizontal scaling second below for additional details
codeintel-janitor
This job periodically removes expired and unreachable code intelligence data and reconciles data between the frontend and codeintel-db database instances.
codeintel-auto-indexing
This job periodically checks for repositories that can be auto-indexed and queues indexing jobs for a remote executor instance to perform. Read how to enable and configure auto-indexing.
insights-job
This job contains all of the backgrounds processes for Code Insights. These processes periodically run and execute different tasks for Code Insights:
- Commit indexer
- Background query executor
- Historical data recorder
- Data clean up jobs
- Settings file insight definition migrations
webhook-log-janitor
This job periodically removes stale log entries for incoming webhooks.
executors-janitor
This job periodically removes old heartbeat records for inactive executor instances.
codemonitors-job
This job contains all the background processes for Code Monitors:
- Periodically execute searches
- Execute actions triggered by searches
- Cleanup of old execution logs
batches-janitor
This job runs the following cleanup tasks related to Batch Changes in the background:
- Metrics exporter for executors
- Changeset reconciler worker resetter
- Bulk operation worker resetter
- Batch spec workspace execution resetter
- Batch spec resolution worker resetter
- Changeset spec expirer
- Execution cache entry cleaner
batches-scheduler
This job runs the Batch Changes changeset scheduler for rollout windows.
batches-reconciler
This job runs the changeset reconciler that publishes, modifies and closes changesets on the code host.
batches-bulk-processor
This job executes the bulk operations in the background.
batches-workspace-resolver
This job runs the workspace resolutions for batch specs. Used for batch changes that are running server-side.
Deploying workers
By default, all of the jobs listed above are registered to a single instance of the worker service. For Sourcegraph instances operating over large data (e.g., a high number of repositories, large monorepos, high commit frequency, or regular precise code intelligence index uploads), a single worker instance may experience low throughput or stability issues.
There are several strategies for improving throughput and stability of the worker service:
1. Scale vertically
Scale the worker service vertically by increasing resources for the service container. Increase the CPU allocation when the service appears CPU-bound and increase the memory allocation when the service consistently uses the majority of its memory allocation or suffers from out-of-memory errors.
The CPU and memory usage of each instance can be viewed in the worker service's Grafana dashboard. Out-of-memory errors will see a sudden rise in memory usage for a particular instance, followed immediately by a new instance coming online.


2. Scale horizontally
Scale the worker service horizontally by increasing the number of running services.
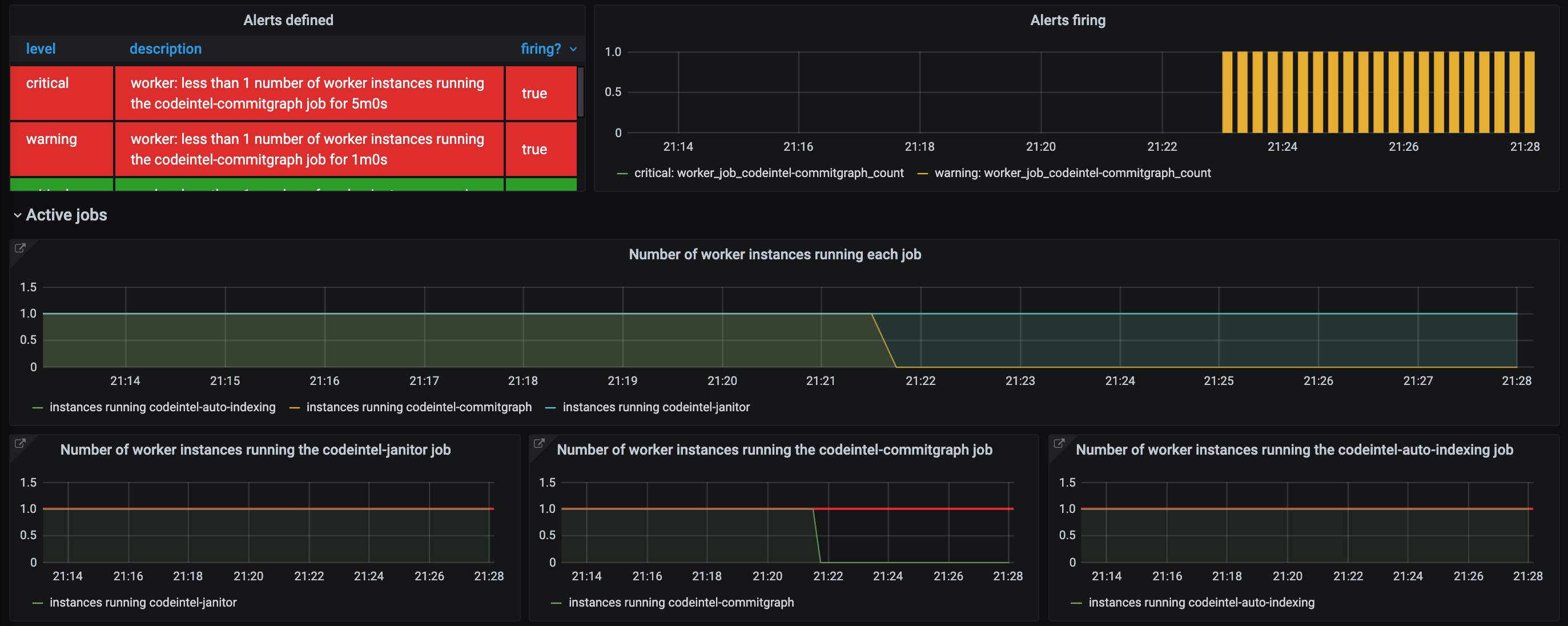
This is an effective strategy for some job types but not others. For example, the codeintel-commitgraph job running over two instances will be able to process the commit graph for two repositories concurrently. However, the codeintel-janitor job mostly issues SQL deletes to the database and is less likely to see a major benefit by increasing the number of containers. Also note that scaling in this manner will not reduce CPU or memory contention between jobs on the same container.
To determine if this strategy is effective for a particular job type, refer to scaling notes for that job in the section above.
3. Split jobs and scale independently
Scale the worker instance by splitting jobs by type into separate functional instances of the worker service. Each resulting instance can be scaled independently as described above.
The jobs that a worker instance runs are be controlled via two environment variables: WORKER_JOB_ALLOWLIST and WORKER_JOB_BLOCKLIST. Each environment variable is a comma-separated list of job names (specified in the section above). A job will run on a worker instance if that job is explicitly listed in the allow list, or the allow list is "all" (the default value), and is not explicitly listed in the block list.
Example
Consider a hypothetical Sourcegraph instance that has a number of repositories with large commit graphs. In this instance, the codeintel-commitgraph job under-performs and several repository commit graphs stay stale for longer than expected before being recalculated. As this job is also heavily memory-bound, we split it into a separate instance (co-located with no other jobs) and increase its memory and replica count.
| Name | Allow list | Block list | CPU | Memory | Replicas |
|---|---|---|---|---|---|
| Worker 1 | all |
codeintel-commitgraph |
2 | 4G | 1 |
| Worker 2 | codeintel-commitgraph |
2 | 8G | 3 |
Now, the codeintel-commitgraph job can process three repository commit graphs concurrently and have enough dedicated memory to ensure that the jobs succeed for the instance's current scale.
Observability
The worker service's Grafana dashboard is configured to show the number of instances processing each job by type and alert if there is no instance processing a particular type of job.
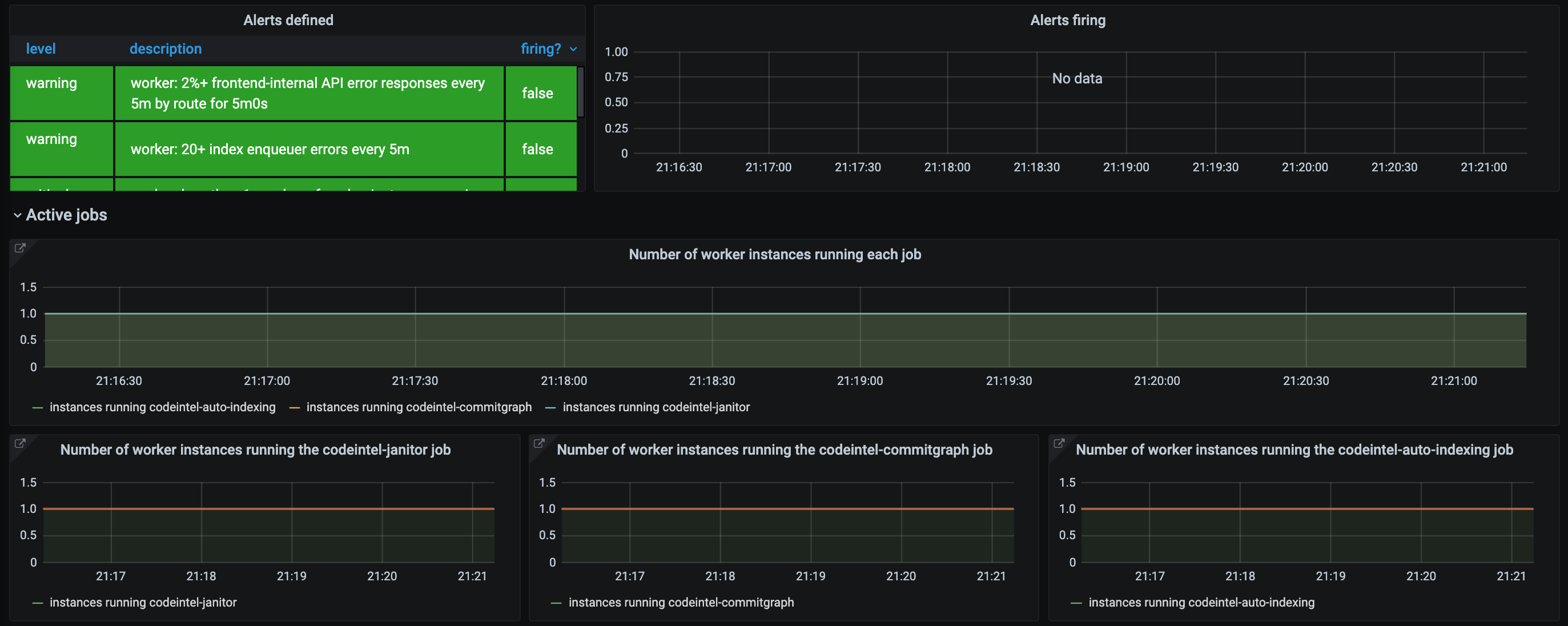
Here is a snapshot of a healthy dashboard, where each job is run by a single worker instance.
Here is a snapshot of an unhealthy dashboard, where no active instance is running the codeintel-commitgraph job (for over five minutes to allow for non-noisy reconfiguration).